Ortelius Blog
Topics include Supply Chain Security, Vulnerability Management, Neat Tricks, and Contributor insights.
The Pros and Cons of GitOps
Understanding the Brilliance and Limitations of GitOps
Before you begin down the GitOps path, you must understand its pros and cons. This blog will cover the fundamentals of GitOps, why it is brilliant, and what are its limitations. Please no hate mail. I know there are many GitOps enthusiasts and for good reason. But like any technology, the path to success is about managing expectations and being fully aware of a technology’s strengths and weaknesses. By understanding them, you can accurately determine if the solution is right for your culture, environment, and process.
GitOps began its journey to solve one primary problem - creating an immutable continuous deployment process around containers and Kubernetes. While it can be expanded to other platforms, it was designed when teams began to containerize their applications to run in a Kubernetes cluster. A containerized application is a monolithic software solution that is built and deployed in a container. All the application dependencies are installed in the container insulating the solution from external changes.
Before we dive into the pros and cons of GitOps, let’s review its fundamentals. GitOps is the management of your Kubernetes cluster by the pull request. GitOps uses a repository of deployment files (normally .yaml) along with a GitOps operator to continually synchronize your cluster to what is stored in Git. In your GitOps model, you will have two Git repositories. One, your source code repository. This is the repository where all of your application-level changes are made. The second repository is an ‘environment’ repository. This repository stores only the deployment .yaml files of your container. It is this repository that is monitored by a GitOps Operator running in your cluster. When the GitOps Operator sees a commit to the ‘environment’ repository, it updates the cluster with the new configuration.
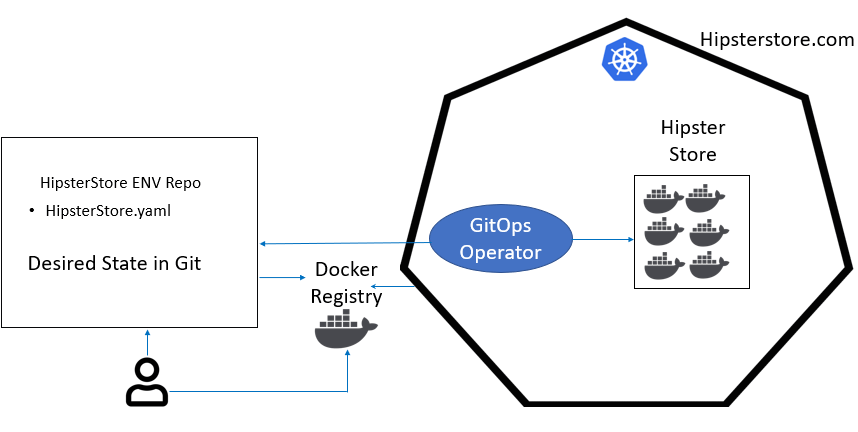
Image 1 - GitOps Basics
- A developer makes an update to the code and commits the changes to Git. A new container image is created and registered (manually or via a pipeline process) which creates a new Container ‘tag.’ This ‘tag’ is unique to that specific container image.
- The developer updates the deployment .yaml file with the new ‘tag’ and commits it back to the Git ‘environment’ repository.
- The GitOps operator sees the new commit and updates the cluster with the new container - brilliant.
This process works similar to the solutions we have seen before. Think Chef and Puppet. Git becomes the master and the GitOps operator becomes the puppet, always performing exactly what Git instructed. This is the brilliance of the GitOps solutions. Without a huge change in the way we work, checking in code, and triggering an action, GitOps has created an airtight deployment process. With this method, we have a high level of confidence that what is stored in Git is running in our cluster. While we will review the pros and cons of GitOps, it must be recognized that the GitOps technology leveraged Git in a clever new way to solve an old problem - eliminating manual manipulation of a deployment script just before deployment.
The Benefits of GitOps
The Pros of GitOps is focused squarely on the benefits of using a version control system to track the changes.
Revisions with history - By using Git, we leverage the power of tracking revisions with history. This means we can compare two .yaml files to see the differences. We know what changes were made, and in most cases, the change can be traced back to a specific incident or change request.
Ownership - Knowing who owns the .yaml file means that you also know who owns the container running in your cluster. In a microservice implementation, knowing the owner of a service is critical when something goes wrong. So without any investment in any other type of tooling, we get this critical information.
Immutable deployments - Ever had that experience where something in the environment has changed but you can’t see what it is? That is probably because someone made a manual update. GitOps makes your deployments ‘airtight’ which is the ultimate goal of GitOps.
Deterministic - No manual updates, please. If someone does make a change to the cluster manually, GitOps will fix that for you based on the .yaml the GitOps operator is watching. This is what creates the ‘single source of truth.’ The state of your cluster is determined by what is stored in Git.
Cluster scaling - GitOps is able to scale to thousands of clusters. Each Cluster uses its own operator to distribute the load.
While we explore both the pros and cons of GitOps, these basic benefits cannot be overlooked. If your path is to manage all of your Kubernetes changes with .yaml files, you should not discount the features that GitOps offers. And it does so with minimal investment in tooling while also supporting a process that your developers are accustomed to - checking in code.
The Challenge of GitOps
Of all of the discussion around the pros and cons of GitOps, scaling is the area that needs the closest look. As noted, one of the benefits of GitOps is the ability for the GitOps operator to easily scale to thousands of clusters. But there is a human element that also must be considered. In GitOps, the deployments are driven by the .yaml file pull request, and the .yaml files are written and managed by DevOps teams.
As you begin managing multiple clusters for your pipeline, each cluster will contain unique configuration values. The script, being imperative, cannot automatically adjust based on the environment. This means that a different deployment script is needed for each environment. This problem grows as you introduce more environments - clusters and Namespaces. And with microservices, the problem grows exponentially.
Scaling a containerized application across the Pipeline - In our “GitOps Basics” example above, we defined the GitOps process from the perspective of a single developer updating a single containerized application into a single cluster. Now let us take a look at how we would manage a containerized application in just 2 additional clusters, giving us a development, test, and production pipeline model. As we add additional environments we must create a separate branch for each of those environments. The GitOps operator watches a different branch to pull the correct version of a container image.
Our pipeline process now requires the developer to update the container ‘tag’ in 3 .yaml files across 3 repositories, development, test, and production. For the most part - doable.
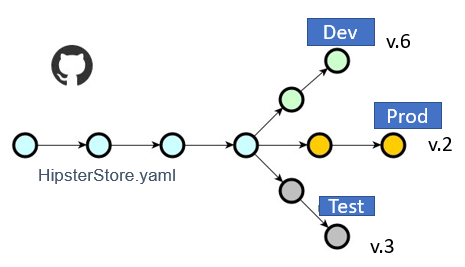
Image 2 - Branching .yaml
Remember we are only required to make multiple updates if the 3 environments use different configuration values. If the values across the clusters are the same, no branching is needed.
Scaling to support Namespaces - A common Kubernetes architecture is to associate ‘applications’ with Namespaces. The implementation resembles a monolithic practice where the application, and any microservices it uses, are siloed. In the example below, we have two websites, the Candy Store and the Hipster Store. They both reuse the Cart, Shipping, and Payment services. The difference between the stores is just their front ends. There are two Git ‘environment’ repositories representing what is needed to run both stores.
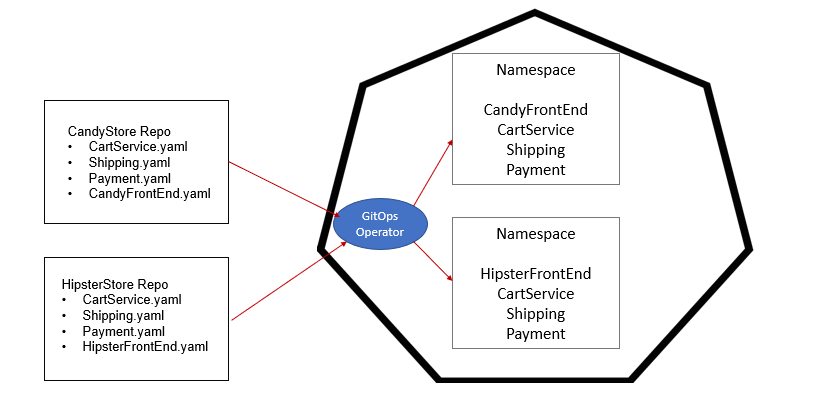
Image 3 - GitOps and Namespaces
If an update is needed to the cart service, the cart service developer needs to know everyone who is consuming the cart service and make the update to each of the .yaml files in the different repositories. And if we have a pipeline, this needs to be done in all environments (dev, test, prod). So if we have two Namespaces and 3 environments that is 24 .yaml files to manage. Alternatively, you could create one big deployment .yaml file for both the Candy Store and Hipster Store, but that makes it more difficult to see who is using which common microservice.
Scaling with a microservice architecture - Kubernetes and microservices were designed to embrace a service-oriented architecture and do so elegantly through its orchestration features. One of the strongest features of a microservice architecture is sharing. The foundation of building a Service Oriented Architecture (SOA) is the reuse of common services across all teams. Making an update to a common service automatically updates all the ‘applications’ that consume the service. Kubernetes does this extremely well and is the core driver of achieving true business agility. An update to a single service can be immediately recognized by all-consuming applications. This can reduce the sprawl of microservices and the number of deployment .yaml files to manage. If each microservice is managed in its own Namespace, the reuse among common services can be leveraged, thus reducing microservice sprawl and the number of deployment .yaml files required.
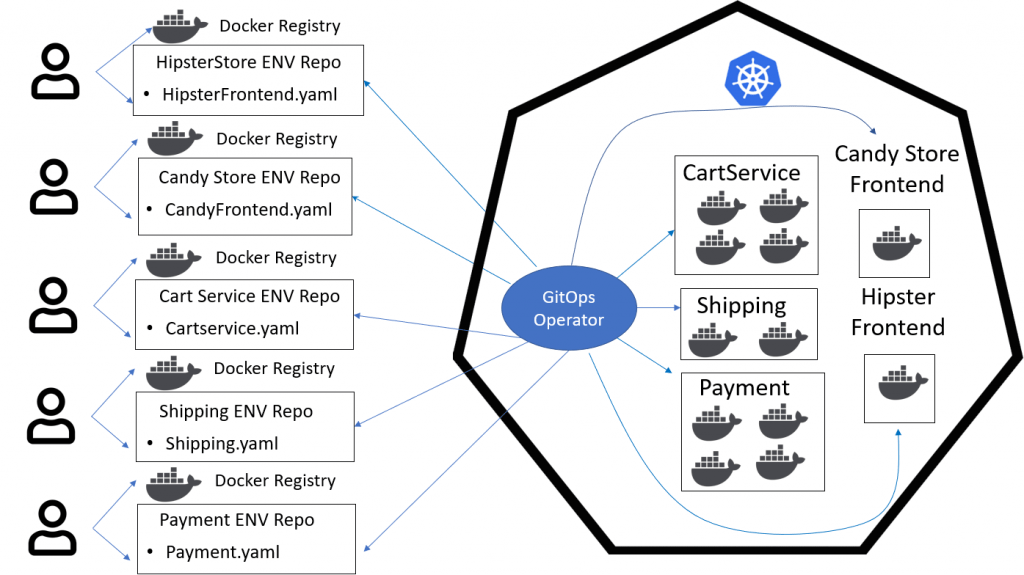
Image 4 - GitOps and Namespaces
Visibility - Critical data is not easily accessible - GitOps relies on the reporting of Git. Unfortunately, much of the critical data that is needed (such as inventory tracking of a particular microservice or what was the last change) is maintained inside of multiple scripts in different branches. When you are trying to address an incident, digging through this data can be somewhat onerous. Better visibility about what changes are moving to the clusters, the tracking of different container versions and inventory is needed.
Conclusion
Exploring the pros and cons of GitOps is an exercise in determining if the solution works for your unique needs. Just like any technology, GitOps has its ‘sweet spots’ but will not solve everyone’s deployment problems - just yet. At the core of GitOps is the ability to create an immutable deployment process with tools and processes that most teams are already leveraging. What could be better? Managing deployments manually is a dangerous process with absolutely no guardrails. GitOps is a way to fix this problem by managing operational tasks via a pull request. But because GitOps is based on a scripted solution, there are inherent limitations. Its reliance on humans to track and update configurations across the cluster makes it difficult to scale to larger microservice and multi-environment architectures.
Ultimately to support hundreds, if not thousands, of microservices moving to dozens of clusters, methods of cataloging microservices, aggregating their relationships, tracking the metadata, and separating the data from the definition will be the direction required by most large enterprises.
As this technology grows, open-source communities and vendors will work to solve some of these challenges. For example, more intelligence and control will be driven by the GitOps operator, managing environment ‘overrides’ to centralize where unique configuration values are updated. Checkout a FluxCD, ArgoCD, and Rancher Fleet. Rancher’s Fleet GitOps operators working to create a GitOps structure that can minimize the number of manual updates required. Even the commercial market is getting involved.Codefresh recently announced their GitOps strategy built into continuous delivery orchestration. The Ortelius Ortelius Open Source Community will be looking at expanding the use of generated deployment .yaml files based on the data stored in the microservice catalog. Those .yaml files can then be committed to the proper environment repository based on a trigger or on-demand. By doing so, scripting is minimized with more visibility into microservice relationships, blast radius, environment overrides, and inventory tracking.
If you are interested in exploring this topic further, the CNCF has started a GitOps Working Group. This group is led by Weaveworks and Codefresh with a focus on defining GitOps and exploring its evolution.
There is no doubt GitOps is the future of continuous deployments. Understanding the pros and cons of GitOps is a path for moving forward and making this technology a common solution designed for a cloud-native world.
About the Author
Tracy is CEO and Co-Founder of DeployHub. She is expert in configuration management and pipeline life cycle practices with a hyper focus on microservices and cloud native architecture. She currently serves as a board member of the Continuous Delivery Foundation and the Executive Director of the Ortelius Open Source project for Microservice Management. Tracy is a recognized evangelist in microservices and the continuous delivery pipeline. She is the creator of the Continuous Delivery Foundation Interactive Landscape, a blog contributor for the CDF, recognized by TechBeacon as on of the top 100 DevOps visionaries and speaks at many DevOps events such as CNCF’s KubeCon and CloudBees DevOps World. Tracy is also a DevOps Institute Ambassador and speaks at AWS Marketplace webinar educational events. She is also the host of the CI/CDF Online Meetups.
