Ortelius Blog
Topics include Supply Chain Security, Vulnerability Management, Neat Tricks, and Contributor insights.
What Metadata is Required for AI DevSecOps?

Creating the Next Generation AI DevSecOps Pipeline
As IT teams strive to bolster software supply chains against hidden vulnerabilities in open-source and third-party components, the demand for smart, streamlined, and automated DevSecOps pipelines is soaring. As monolithic applications evolve into intricate, decoupled parts, navigating the security landscape becomes increasingly complex.
To address these challenges, DevSecOps automation is stepping in to streamline software security tasks, sparing IT teams from drowning in manual work. The integration of ‘applied’ AI into DevOps heralds the dawn of next-generation DevSecOps pipelines, harnessing a wealth of data sources to refine processes, empower decision-making, and perform continuous vulnerability management, critical to weathering the code-level cybersecurity storm.
At Ortelius, our focus lies in gathering and centralizing data from various DevSecOps processes to forge the path towards the next era of DevSecOps pipelines. Modern pipelines must effectively harness AI and automate risk assessment, package management, vulnerability management, and remediation.
However, a key obstacle in realizing this vision is the fragmented nature of DevSecOps data storage. Security results, like Software Bill of Materials Reports (SBOM), reside in scattered text files, while software composition analysis outputs are confined within individual tools. Build and deployment results linger in logs, and a comprehensive historical record of the entire DevSecOps journey remains decentralized. To address this challenge, Ortelius aggregates and centralizes data from diverse DevOps processes.
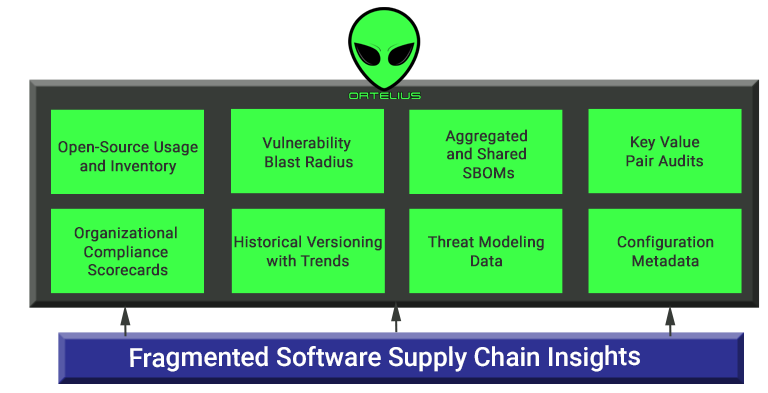
This data serves as the cornerstone for effective AI application, enabling the generation of risk assessments, package management strategies, zero trust policies, vulnerability management protocols, and remediation actions. With centralized and harmonized data, the path to a truly transformative DevSecOps future becomes clear.
Applying AI to the DevSecOps data could produce the following use cases:
-
Determine if a repository is high risk and prevent the use of the associated package from being consumed. AI algorithms could be defined to locate a replacement package from a repository that is low-risk.
-
Determine why a repository is high-risk, and produce the needed security tools to fix the issues. For example, if no dependency tool is used (Dependabot / Renovate), then auto-configure a dependency tool. Other tools such as fuzzing and linting could also be automatically configured and added to reduce the risk of the project’s repository.
-
Ensure that old versions of open-source and third-party packages are not consumed and instead use the latest release of the package, ignoring what is statically listed in the build process.
-
Report and remove a package in the build that is never used. Unused packages add security risks to the artifact and should be removed.
-
Automatically remediate a known vulnerability by rebuilding and deploying the artifacts.
-
Historical data could be used to evaluate threat models, determine their accuracy and generate new models.
-
Analyze company wide usage of open-source to predict the most critically consumed packages and recommend minimizing the risk from overused components.
To recognize the above benefits, AI needs data. Following is the type of data that Ortelius collects that is the basis for future AI in DevSecOps:
Repositiory Data
- OpenSSF Scorecard data
- list of contributors
- last commit was signed and verified status
- the git signature
- read.me
- license files
- swagger details
Build Data
Build data is generated at the time an artifact is created using tools such as Docker, compilers, and package managers. During the build, Ortelius collects:
- SBOMs package dependencies and versions
- vulnerabilities associated to the SBOMs
- CI/CD Build Number
- Git commit
- Git Commit timestamp
- Git UserID that created the Commit
- Git Repository and branch
- Git commit signed and verified status
- Git commit signature
- the number of contributors to the repository
- the build URL and log location
- build timestamp
- build process (Docker registry, Docker Tag, Docker SHA)
- SonarQube or Veracode results
Deployment and Enviornment Data
- artifact version deployed
- installed location (cluster/servers)
- inventory of open-source and 3rd party package per environment
- key value pairs
- deployed by who and when
- deployment process (helm chart)
- version drift between environments.
Historical Trends
- component versions with a snapshot of all of the above data
- logical application versions with a snapshot of all of the above data
- environment updates showing deployment changes
- comparisons between any two components, logical applications and environments.
Conclusion:
Ortelius centralizes and aggregates all of the above DevSecOps data to make it actionable, and available for applying AI to the DevSecOps process and creating a next generation of pipeline. By leveraging these types of data, Ortelius can effectively integrate AI into the DevSecOps processes to automate vulnerability response, build strong zero trust policies, improve threat models and enhance system reliability, without slowing down software delivery.
