Ortelius Blog
Topics include Supply Chain Security, Vulnerability Management, Neat Tricks, and Contributor insights.
How to Bake an Ortelius Pi Part 3 | The GitOps Configuration
- Introduction
- Kubernetes
- Enter GitOps | Enter Gimlet | Enter Fluxcd
- Gimlet
- Fluxcd
- Gimlet Installation
- Gimlet GitOps Infrastructure
- Kubernetes CSI NFS Driver Deployment
- Helm-Repository | CSI NFS Driver
- Helm-Release | CSI NFS Driver
- NFS Architecture
- NFS Observations
- NFS Netdata Observations
- Update
- Mount Permissions
- Fluxcd is doing the following under the hood | CSI NFS Driver
- Kubernetes check | CSI NFS Driver
- Kubernetes Cert Manager Deployment
- Helm-Repository | Cert Manager
- Helm-Release | Cert Manager
- Helm Chart Configuration Highlights
- Fluxcd is doing the following under the hood | Cert Manager
- Kubernetes check | Cert Manager
- Metallb Load-Balancer For Bare Metal Kubernetes Deployment
- Helm-Repository | Metallb
- Helm-Release | Metallb
- Fluxcd is doing the following under the hood | Metallb
- Kubernetes check | Metallb
- Traefik the Cloud Native Proxy Deployment
- Helm-Repository | Traefik
- Helm-Release | Traefik
- Helm Chart Configuration Highlights
- Gimlet Manifest Folder | Traefik
- Fluxcd is doing the following under the hood | Traefik
- Traefik Dashboard
- Further reading | Traefik
- Ortelius The Ultimate Evidence Store
- Ortelius Microservice GitHub repos
- Helm-Repository | Ortelius
- Helm-Release | Ortelius
- Fluxcd is doing the following under the hood | Ortelius
- Kubernetes check | Ortelius
- Conclusion
- Next Steps
Introduction
In part 2, of this series we deployed DHCP, DNS, NFS with a Synology NAS and deployed MicroK8s in HA mode.
In part 3 we will use the GitOps Methodology to deploy Cert Manager, NFS CSI Driver for Kubernetes to connect to the Synology NAS for centralised dynamic volume storage, Metallb Load Balancer, Traefik Proxy as the entrypoint for our Microservices and Ortelius the ultimate evidence store using Gimlet as the UI to our GitOps controller Fluxcd.
I have included the full Helm Chart values.yaml configuration from the provider to provide an educational element. In contrast to this I could just show the changes thus making less lines of code and a whole lot less scrolling but I wanted to give a full picture of the configuration and layout the application like a block of clay that you will shape to suit your needs.
Kubernetes
CRDs
CRDs are custom resources created in our Kubernetes cluster that add additional functionality and most of the infrastructure components you will be deploying will create CRDs in your Kubernetes cluster.
kubectl get crds --all-namespaces
Context and Namespace Switching
All the context and name space switching can get really tedious so I introduce to you a wonderful tool called KubeSwitch. In the below step-by-step I show you how I set mine up.
- Kubeswitch on Github
- The case of Kubeswitch
- Unified search over multiple providers
- Change namespace
- Change to any context and namespace from the history
- Terminal window isolation
- Advanced search capabilties
Steps to setup KubeSwitch
- Install KubeSwitch here
- Configure KubeSwitch by creating a
switch-config.yamlfile in your home folder in.kube/switch-config.yaml
kind: SwitchConfig
version: v1alpha1
kubeconfigName: "config*"
showPreview: true
execShell: null
refreshIndexAfter: null
hooks: []
kubeconfigStores:
- kind: filesystem
kubeconfigName: "config*"
paths:
- "~/.kube"
- Create a folder structure for your many client clusters like this:
.kube/config
.kube/cfg/i1/config-i1
.kube/cfg/pangarabbit/config-pr
- Kubeswitch will search
config*in the.kubedirectory in your home folder so that when I typeswitchon the command line I get a fuzzy search list of my Kubernetes contexts which I can just select from a list:
.kube/kind-ortelius │ │
.kube/kind-kind │ │
.kube/docker-desktop │ │
pangarabbit/microk8s │ │
i1/microk8s-i1 │ │
kind-ortelius │ │
kind-kind │ │
docker-desktop │ │
.switch_tmp/microk8s-i1 │ │
> .switch_tmp/microk8s
- My aliases and autocompletion for Kubeswitch in
.zshrc
alias sw='switch'
alias swclean='switch clean'
alias swexec='switch exec '
alias swgardener='switch gardener'
alias swhelp='switch help'
alias swhist='switch history'
alias swhooks='switch hooks'
alias swlcon='switch list-contexts'
alias swns='switch namespace '
alias swscon='switch set-context '
alias swslcon='switch set-last-context'
alias swspcon='switch set-previous-context'
alias swver='switch version'
# Auto completion for Kubeswitch in zsh shell
source <(switcher init zsh)
Enter GitOps | Enter Gimlet | Enter Fluxcd
I wanted to find a process for repeatable deployments, and to incorporate drift detection for Kubernetes infrastructure and applications but I was finding it heavy going to use the default values from the providers Helm Chart and then trying to override those with my own values. I couldn’t get that to work without some hellish complicated setup until I found Gimlet and Fluxcd which allowed for a single human to have a simple repeatable process.
Gimlet gives us a clean UI for Fluxcd and allows us to have a neat interface into the deployments of our infrastructure and applications. Basically like having the Little Green Mall Wizard in your K8s cluster.
Gimlet
- Documentation
- Managing infrastructure components
- On the command line
- Gimlet manifest reference
- Gimlet OneChart reference
- Gimlet configuration reference
- Upgrading Flux
Gimlet uses the concepts of Kubernetes infrastructure and Kubernetes applications. The infrastructure concept is the bedrock to deploy applications in an environment containing security, observability, storage, load balancer, proxy API services, Ortelius and anything else your applications depend on. Applications would be the services you provide to end users and customers. This concept is fundamental to understanding the ways of Gimlet and Fluxcd.
Gimlet comes in two flavours Self-Hosted and Cloud hosted. I am using Cloud hosted due to the very generous humans at Gimlet.
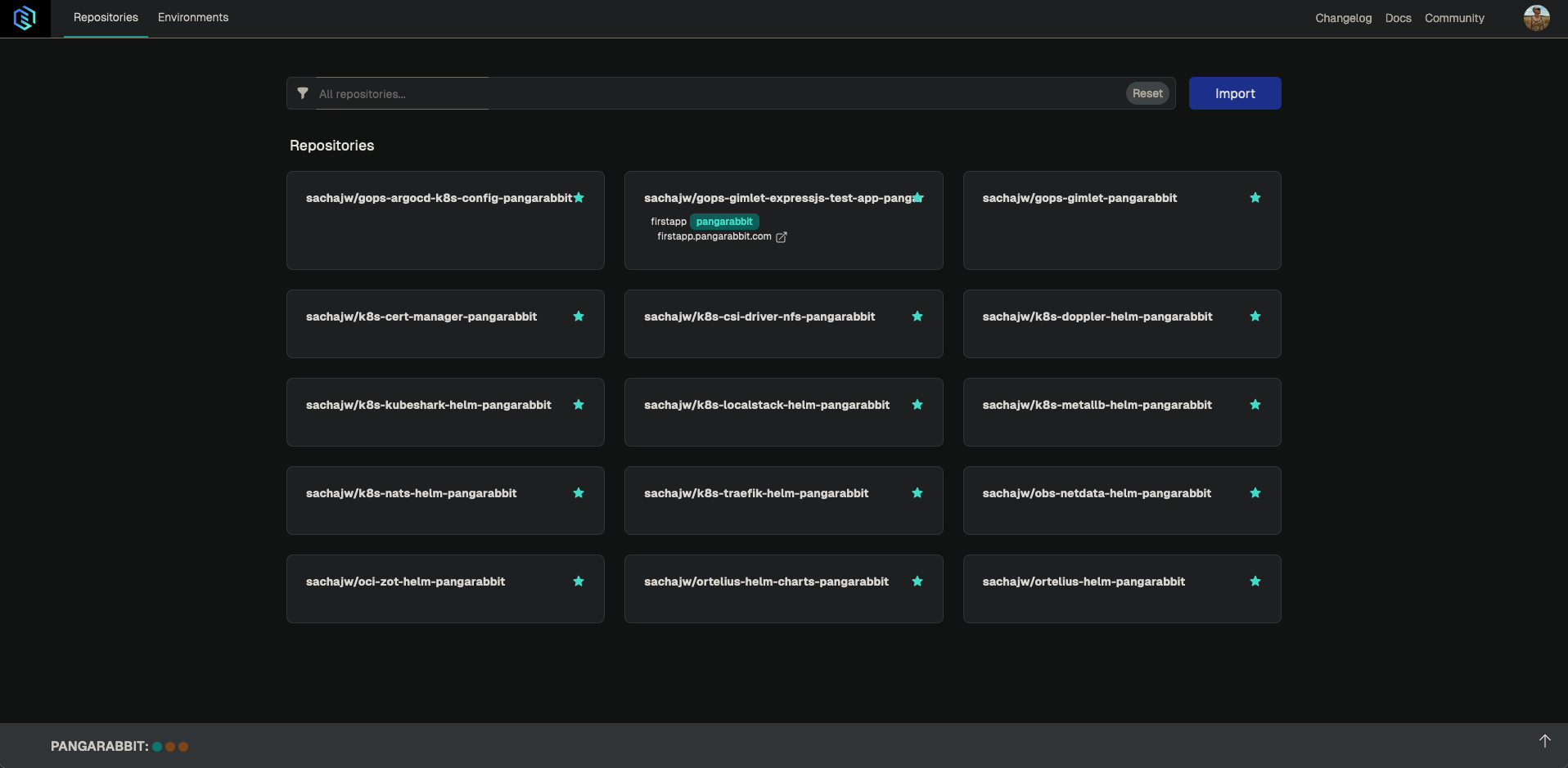
Gimlet Application Repostories
- When the Gimlet dashboard loads you will be met with the repostories section which is where you import your
applicationrepos to be managed by the GitOps process
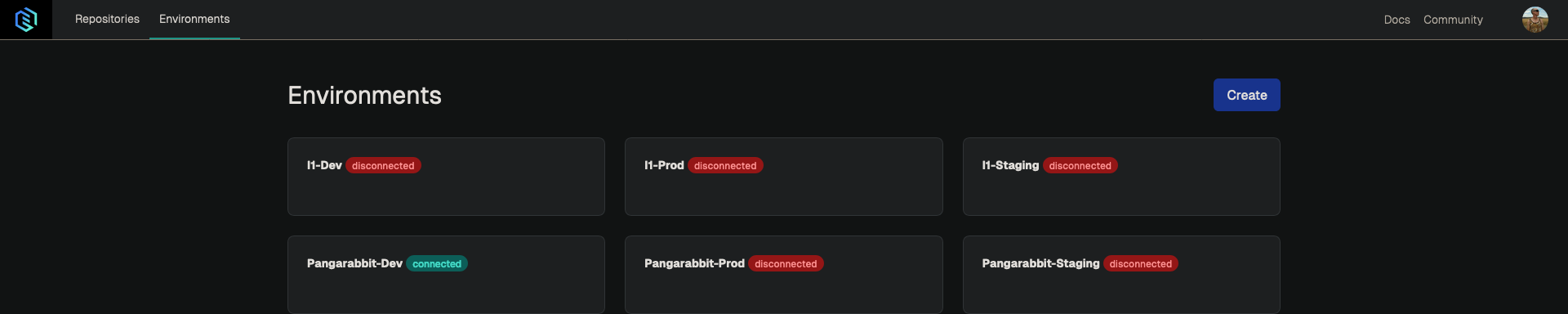
Gimlet Environments
- Environments are the representation of your journey to getting your applications to the end user such as dev, staging and production
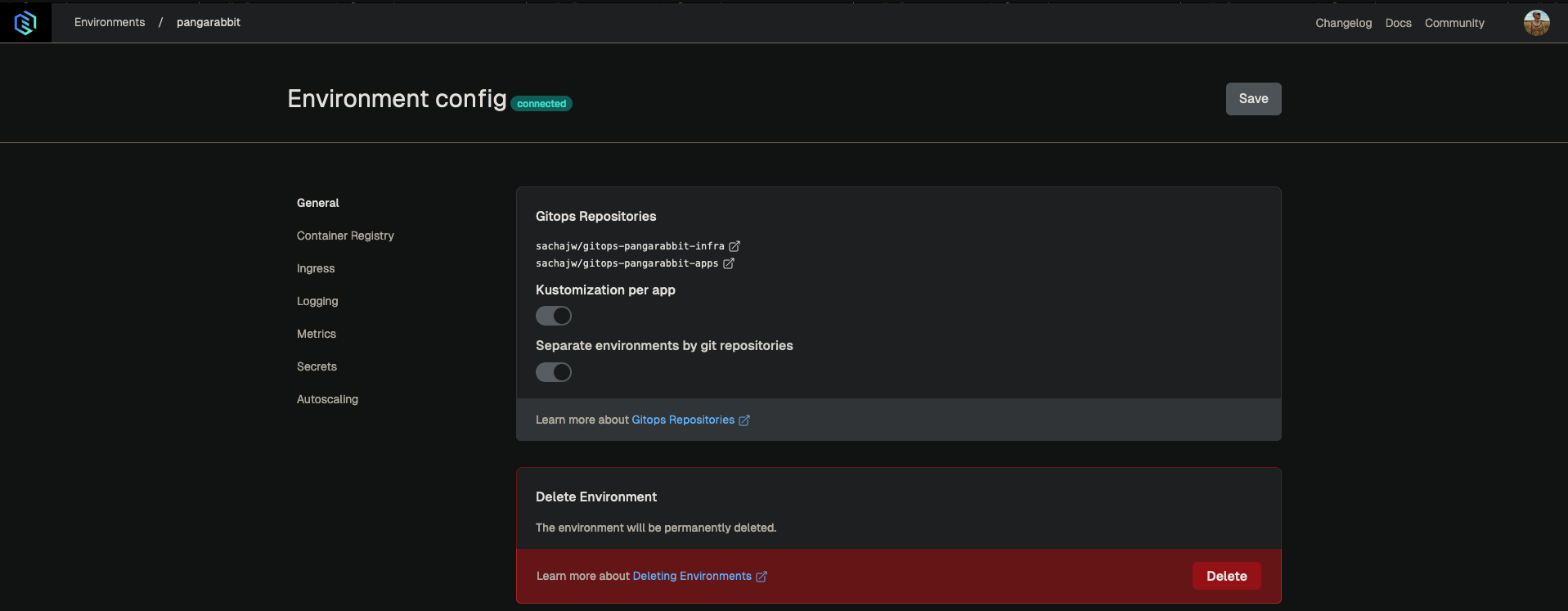
Gimlet Environment Config
- These are pre baked in environment configs which can be turned on and off with a toggle
Gimlet Observability
- This is where you can cycle through different elements of the GitOps process and get feedback on deployments
- Click on the environment name at the bottom left of the interface

- The
Flux Runtimeshows you exactly what Flux is chewing on and gives the operator visuals into whats going on in the environment - Click on
Logsto get logs - Click
Describeto run akubectl describe
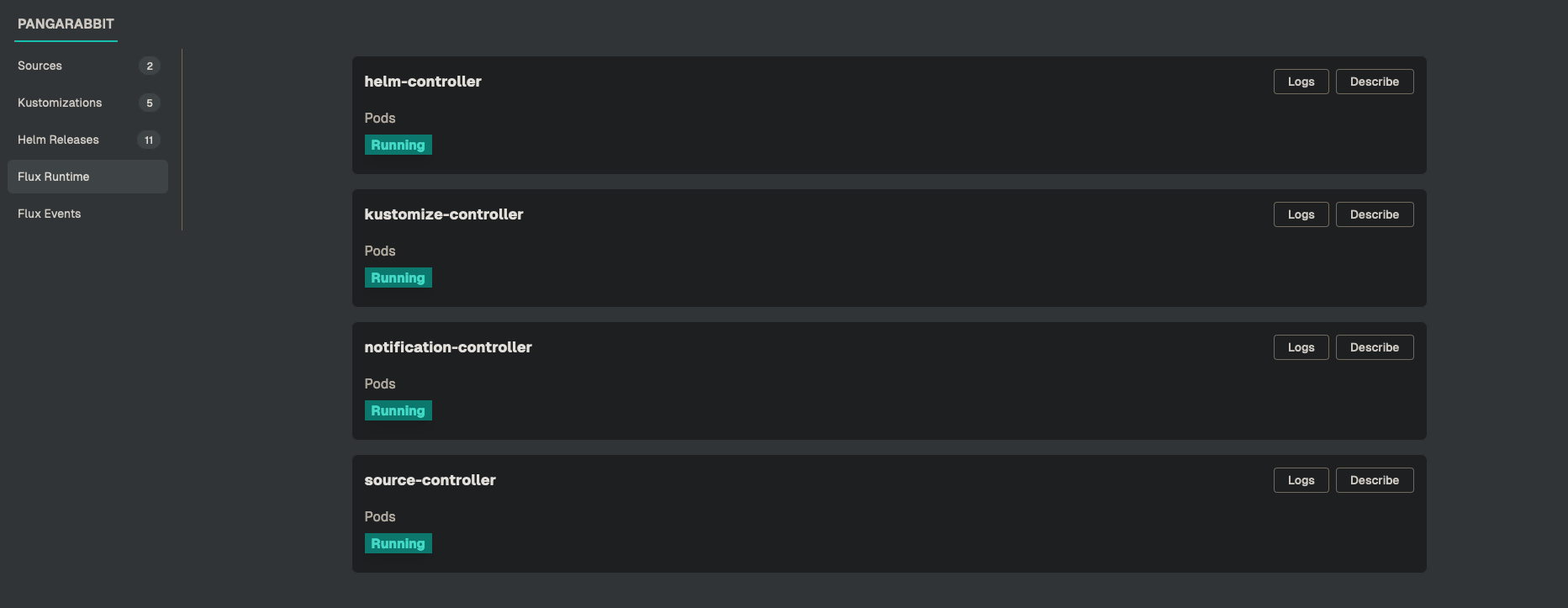
As you can see Gimlet is the human friendly inteface into the inner workings of Fluxcd our GitOps Operator. The Gimlet team have done a fantastic job to make this possible. Please go and check out Gimlet
Fluxcd
FluxCD is a powerful, open-source GitOps tool designed to automate the continuous delivery (CD) of applications in Kubernetes. It enables a Git-centric approach to deploying and managing Kubernetes clusters, where the desired state of the system is defined in version-controlled repositories (like Git), and Flux ensures that the cluster always stays in sync with this state.
By automating the reconciliation of cluster state with the contents of your Git repository, Flux simplifies deployment workflows, improves reliability, and brings better control over application releases. Whether you’re scaling microservices, rolling out updates, or managing infrastructure, FluxCD empowers teams to manage Kubernetes environments with increased confidence and efficiency.
VS Code Extension
The VS Code extension allows you to get into the guts of your Fluxcd deployment, Fluxcd configuration and Fluxcd troubleshooting from within VS Code.
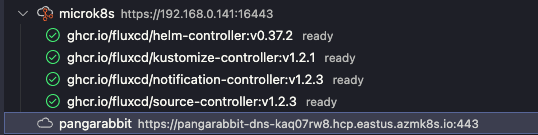
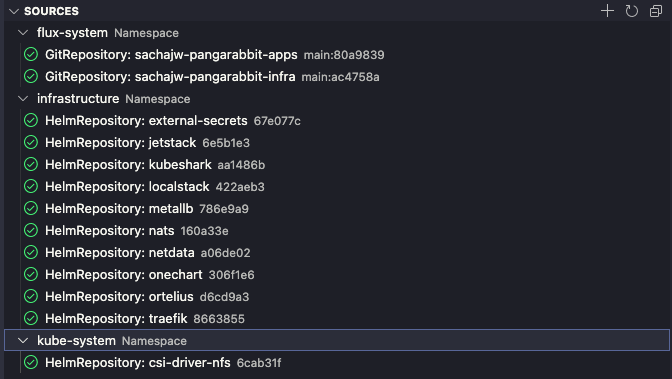
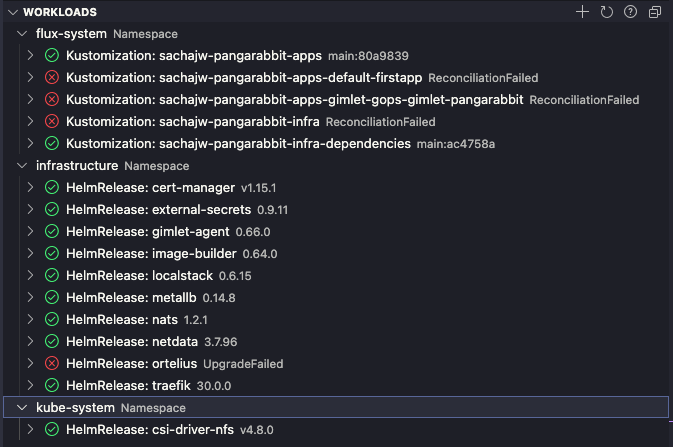
Flux CRD’s
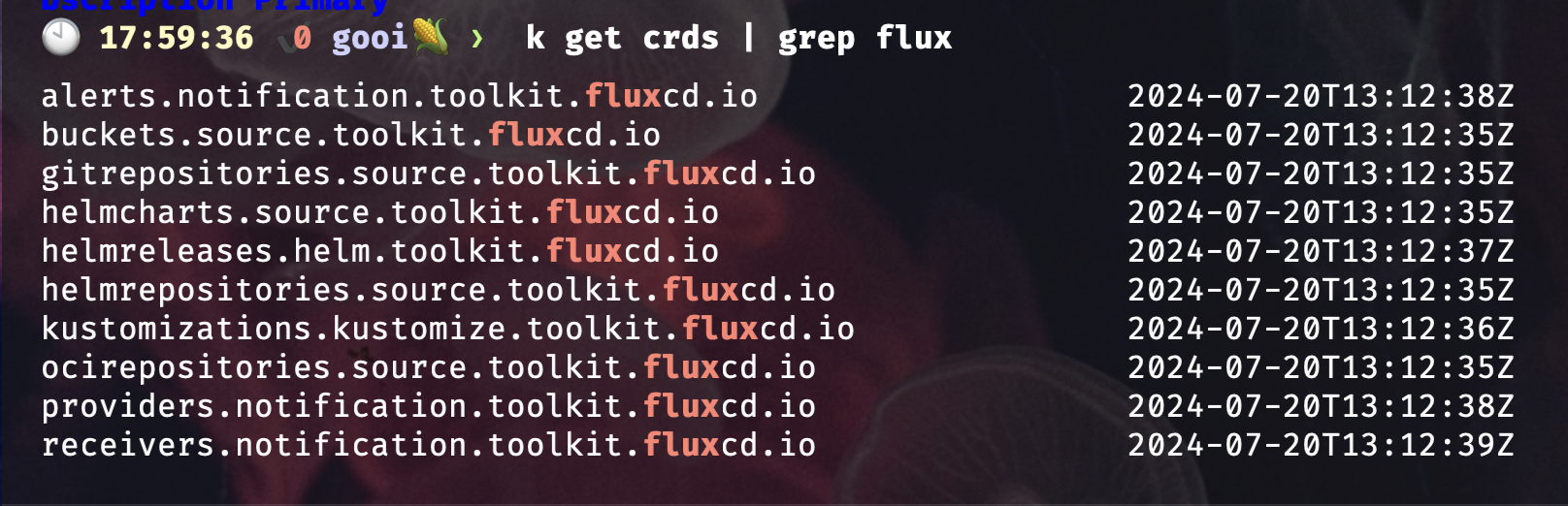
Lets take a look at the Flux CRD’s.
`kubectl get crds | grep flux`
Gimlet Installation
Prerequisites
- You will need to have an account with a provider such as Github which is the provider I use
- Gimlet is going to use this provider for all things GitOps
- Install Gimlet CLI
# Check the current version before you install
curl -L "https://github.com/gimlet-io/gimlet/releases/download/cli-v0.27.0/gimlet-$(uname)-$(uname -m)" -o gimlet
chmod +x gimlet
sudo mv ./gimlet /usr/local/bin/gimlet
gimlet --version
Gimlet on the command line
FYIplease read this On the command line- We will be spending all of our time in the
gitops-<your-environment>-infrarepo to deploy our Kubernetes infrastructure with Gimlet
Install Gimlet
- Explore more involved installations of Gimlet here
- We will be using this easy to deploy one-liner for now
- Whether you use the cloud or the self-hosted version the interface is the same
- You won’t need to port forward to the UI if you use cloud hosted as the Gimlet folks do the hard work for you
- As a hint you could enable the
ingressand set theingressClasstotraefikand access the interface from your local network e.g.gimlet.pangarabbit.comthus negating port forwarding
kubectl apply -f https://raw.githubusercontent.com/gimlet-io/gimlet/main/deploy/gimlet.yaml
- Then access it with port-forward on http://127.0.0.1:9000
kubectl port-forward svc/gimlet 9000:9000
- Login with Github

- Or you will get a screen like this to login with an
admin key

- To find the admin key, type this command in the terminal
kubectl logs deploy/gimlet | grep "Admin auth key"
time="2023-07-14T14:28:59Z" level=info msg="Admin auth key: 1c04722af2e830c319e590xxxxxxxx" file="[dashboard.go:55]"
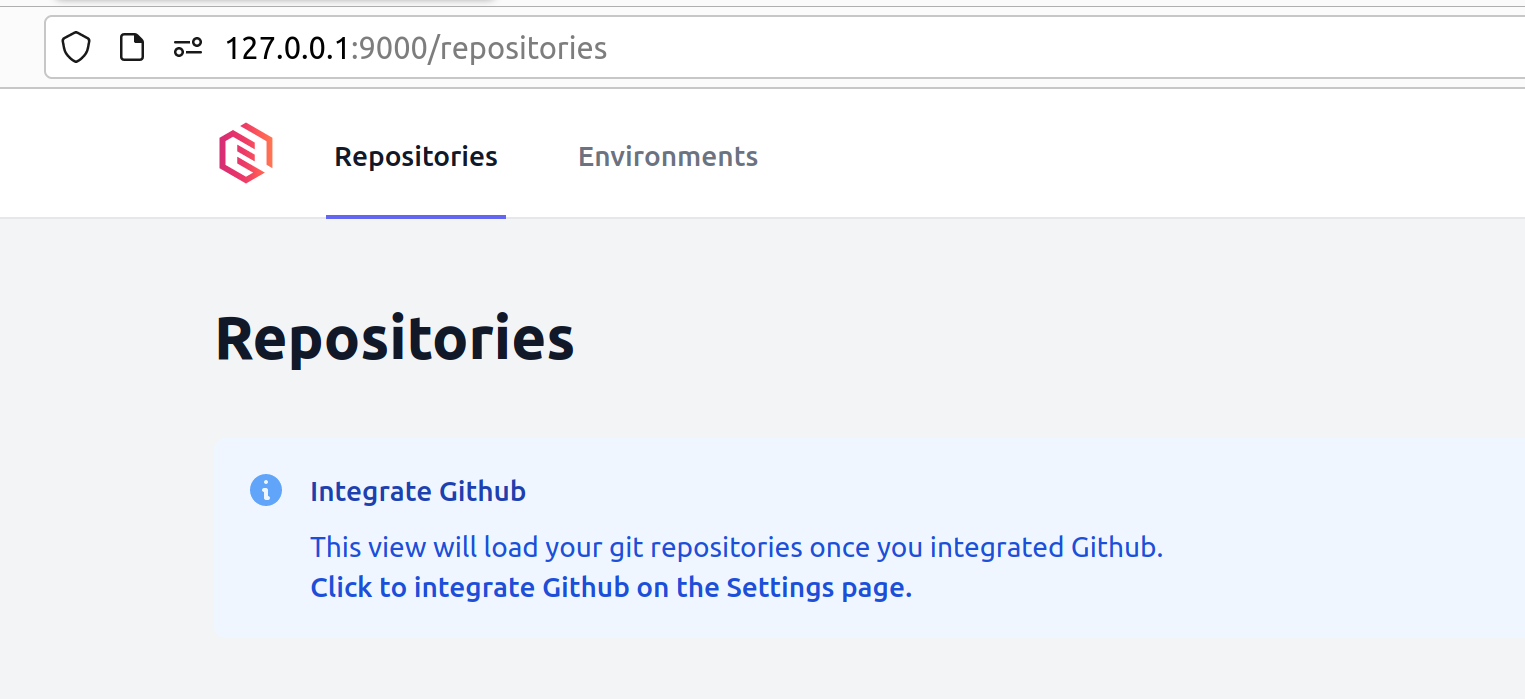
Connect your repositories
- Only import your application repositories here and not anything to do with infrastructure
Connect you cluster
- Connect your K8s cluster to Gimlet
gimlet environment connect \
--env <your environment such as dev or staging or test or prod or anything you like> \
--server https://app.gimlet.io \
--token <your token>
K8s check
- Now if you list your namespaces with the below command you should see
infrastructure,fluxandflux-system
kubectl get namespaces
- Switch to the namespace
infrastructure
kubectl config set-context --current --namespace=infrastructure
- List pods and you should see
gimlet-agent-<gooey-string>
kubectl get pods
Github check
- Go to Github.com and click on your profile in the top right hand corner of your browser tab
- Scroll down until the left hand coloumn shows
Applicationsunder the titleIntegrations
- You should see the Gimlet application installed
!!!WARNING!!!Whatever you do don’t just delete this app like I did and get yourself into an account mess

Github Gimlet repo check
- Click on repositories at the top left of the screen

- Then type
gitops-in the search bar and you should see two repos pop up
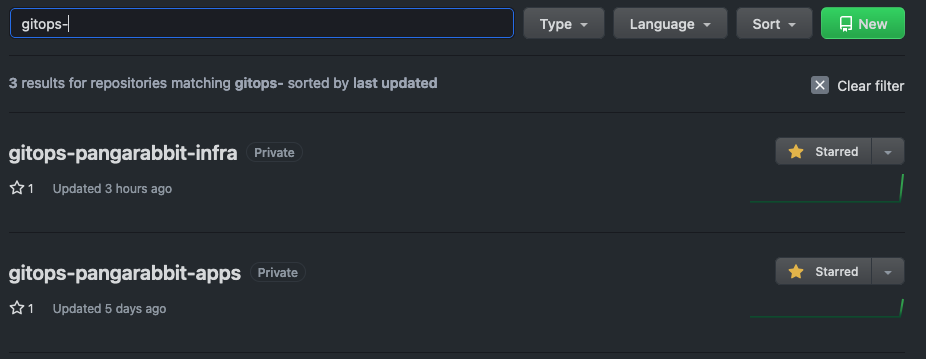
- You should see
gitops-<your-environment>-infraandgitops-<your-environment>-apps - You will notice that this repo is private thus no one can see any sensitive information such as secrets
- I will be including Doppler later for secrets management
- Clone this repo to your local machine
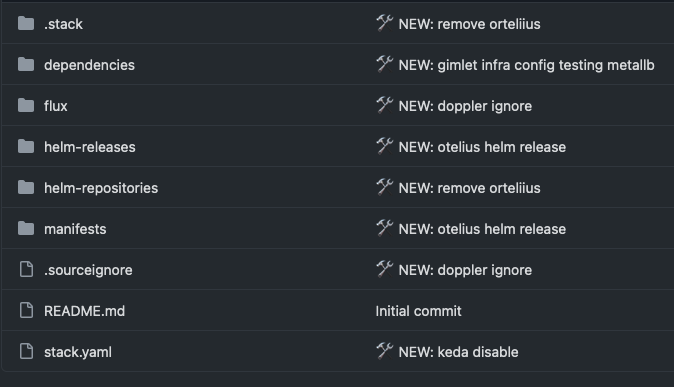
Gimlet Gitops Infra
- Once we have added configuration in
helm-repositoriesandhelm-releaseand performed agit push, Fluxcd will manage the entire deployment process to the Kubernetes cluster and give feedback as to the status of the deployment in the Gimlet UI
Gimlet Gitops Applications
- Use the Gimlet walkthrough here to deploy your
firstappif you can’t wait for the blog post
git clone https://github.com/<your-profile>/gitops-<your-environment>-infra.git
git clone https://github.com/<your-profile>/gitops-<your-environment>-apps.git
- On your local machine open your IDE and navigate to your cloned infrastructure repo
Gimlet GitOps Infrastructure
Kubernetes CSI NFS Driver Deployment
With the NFS CSI Driver we will use Kubernetes to dynamically manage the creation and mounting of persistent volumes to our pods using the Synology NAS as the central storage server.
- Kubectl quick reference here
- Helm cheat sheet here
- Helm Chart reference here
- Kubernetes Storage Class docs here
- What is network-attached storage (NAS)?
- What is NFS?
- An excellent blog written by Rudi Martinsen on the NFS CSI Driver with step-by-step instructions for reference here
- Basic NFS Security - NFS, no_root_squash and SUID
Helm-Repository | CSI NFS Driver
- Lets add the Kubernetes CSI NFS Driver Helm repository
- A Helm repository is a collection of Helm charts that are made available for download and installation
- Helm repositories serve as centralised locations where Helm charts can be stored, shared, and managed
- Create a file called
nfs-csi-driver.yamlin thehelm-repositoriesdirectory and paste the following YAML
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: csi-driver-nfs
namespace: kube-system
spec:
interval: 60m
url: https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts
Helm-Release | CSI NFS Driver
- Lets create a Helm release of the Kubernetes CSI NFS Driver
- A Helm release is an instance of a Helm chart running in a Kubernetes cluster
- Each release is a deployment of a particular version of a chart with a specific configuration
- Create a file called
nfs-csi-driver.yamlin thehelm-releasesdirectory and paste the following YAML
NFS Architecture
In my setup I opted to create a storage class for Jenkins, Netdata, Traefik and Localstack so that I could troubleshoot storage classes on an individual bases without affecting the entire cluster.
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-csi-jenkins nfs.csi.k8s.io Retain Immediate true 27d
nfs-csi-localstack nfs.csi.k8s.io Retain Immediate true 27d
nfs-csi-traefik nfs.csi.k8s.io Retain Immediate true 27d
pi8s-nfs-netdata (default) microk8s.io/hostpath Retain Immediate true 113m
NFS Observations
- Once I deployed the storage class config you cannot change the parameters without deleting the original, making your changes and then redeploying the storage class.
NFS Netdata Observations
- For Netdata even thou I specified the storage classes in the Helm Chart that Netdata should use it would always use the default storage class so I created a Netdata storage class and made that the default.
pi8s-nfs-netdata (default) microk8s.io/hostpath Retain Immediate true 115m
I tried all kinds of NFS hacks and configurations using the CSI NFS Driver to get the Netdata parent to persist data to the Synology DS413j NFS share at 192.168.0.152/pi8s/netdata to work but I failed. It would read/write perfectly for a while then it would die after a period of time with being unable to chown (change ownership). Oddly the persistence for K8s state was fine.
It might seem a bit mad to show the log file but this is a good illustration of challenges you can face with infrastructure. From my investigations the 201:201 represents the entity netdata which cannot chown (change ownership)
# Logs from the netdata-parent pod
kubectl logs netdata-parent-97687dd89-x7wz9
2024/10/16 09:07:53.0718: [ 1]: WARNING: mongoc: Falling back to malloc for counters.
time=2024-10-16T09:07:53.721+00:00 comm=netdata source=daemon level=info errno="2, No such file or directory" tid=1 msg="CONFIG: cannot load cloud config '/var/lib/netdata/cloud.d/cloud.conf'. Running with internal defaults."
time=2024-10-16T09:07:53.721+00:00 comm=netdata source=daemon level=error errno="2, No such file or directory" tid=1 msg="Ignoring host prefix '/host': path '/host/proc' failed to statfs()"
time=2024-10-16T09:07:53.723+00:00 comm=netdata source=daemon level=info tid=1 msg="Netdata agent version 'v1.47.4' is starting"
time=2024-10-16T09:07:53.723+00:00 comm=netdata source=daemon level=info tid=1 msg="IEEE754: system is using IEEE754 DOUBLE PRECISION values"
time=2024-10-16T09:07:53.723+00:00 comm=netdata source=daemon level=info tid=1 msg="TIMEZONE: using the contents of /etc/timezone"
time=2024-10-16T09:07:53.723+00:00 comm=netdata source=daemon level=info tid=1 msg="TIMEZONE: fixed as 'Etc/UTC'"
time=2024-10-16T09:07:53.724+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: next: initialize signals"
time=2024-10-16T09:07:53.724+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 0 ms, initialize signals - next: initialize static threads"
time=2024-10-16T09:07:53.724+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 0 ms, initialize static threads - next: initialize web server"
time=2024-10-16T09:07:53.724+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 0 ms, initialize web server - next: initialize ML"
time=2024-10-16T09:07:54.106+00:00 comm=netdata source=daemon level=info tid=1 msg="ml database version is 2 (no migration needed)"
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 427 ms, initialize ML - next: initialize h2o server"
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 0 ms, initialize h2o server - next: set resource limits"
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="resources control: allowed file descriptors: soft = 65536, max = 65536"
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 0 ms, set resource limits - next: become daemon"
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="Out-Of-Memory (OOM) score is already set to the wanted value 1000"
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="Adjusted netdata scheduling policy to batch (3), with priority 0."
time=2024-10-16T09:07:54.152+00:00 comm=netdata source=daemon level=info tid=1 msg="Running with process scheduling policy 'batch', nice level 19"
time=2024-10-16T09:07:54.164+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/cache/netdata' to 201:201"
time=2024-10-16T09:07:54.164+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/ml.db' to 201:201"
time=2024-10-16T09:07:54.166+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/ml.db-wal' to 201:201"
time=2024-10-16T09:07:54.166+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/ml.db-shm' to 201:201"
time=2024-10-16T09:07:54.166+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/netdata-meta.db' to 201:201"
time=2024-10-16T09:07:54.167+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/netdata-meta.db-wal' to 201:201"
time=2024-10-16T09:07:54.167+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/netdata-meta.db-shm' to 201:201"
time=2024-10-16T09:07:54.167+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/context-meta.db' to 201:201"
time=2024-10-16T09:07:54.167+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/context-meta.db-wal' to 201:201"
time=2024-10-16T09:07:54.168+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/context-meta.db-shm' to 201:201"
time=2024-10-16T09:07:54.168+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/cache/netdata/dbengine' to 201:201"
time=2024-10-16T09:07:54.169+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/dbengine/datafile-1-0000000001.ndf' to 201:201"
time=2024-10-16T09:07:54.169+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/dbengine/journalfile-1-0000000001.njf' to 201:201"
time=2024-10-16T09:07:54.169+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/dbengine/datafile-1-0000000002.ndf' to 201:201"
time=2024-10-16T09:07:54.170+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/dbengine/journalfile-1-0000000002.njf' to 201:201"
time=2024-10-16T09:07:54.170+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/cache/netdata/dbengine/journalfile-1-0000000001.njfv2' to 201:201"
time=2024-10-16T09:07:54.170+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/cache/netdata/dbengine-tier1' to 201:201"
time=2024-10-16T09:07:54.171+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/cache/netdata/dbengine-tier2' to 201:201"
time=2024-10-16T09:07:54.172+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/lib/netdata' to 201:201"
time=2024-10-16T09:07:54.173+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/lib/netdata/netdata_random_session_id' to 201:201"
time=2024-10-16T09:07:54.173+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/lib/netdata/netdata.api.key' to 201:201"
time=2024-10-16T09:07:54.174+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/lib/netdata/.agent_crash' to 201:201"
time=2024-10-16T09:07:54.174+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/lib/netdata/lock' to 201:201"
time=2024-10-16T09:07:54.175+00:00 comm=netdata source=daemon level=error errno="2, No such file or directory" tid=1 msg="Cannot chown directory '/var/lib/netdata/cloud.d' to 201:201"
time=2024-10-16T09:07:54.175+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown directory '/var/lib/netdata/registry' to 201:201"
time=2024-10-16T09:07:54.176+00:00 comm=netdata source=daemon level=error errno="22, Invalid argument" tid=1 msg="Cannot chown file '/var/lib/netdata/registry/netdata.public.unique.id' to 201:201"
time=2024-10-16T09:07:54.177+00:00 comm=netdata source=collector level=error errno="13, Permission denied" tid=1 msg="Runtime directory '/var/cache/netdata' is not writable, falling back to '/tmp'"
time=2024-10-16T09:07:54.181+00:00 comm=netdata source=daemon level=info errno="17, File exists" tid=1 msg="netdata started on pid 1."
time=2024-10-16T09:07:54.181+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 28 ms, become daemon - next: initialize threads after fork"
time=2024-10-16T09:07:54.181+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 0 ms, initialize threads after fork - next: initialize registry"
time=2024-10-16T09:07:54.183+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 2 ms, initialize registry - next: collecting system info"
time=2024-10-16T09:07:55.345+00:00 comm=netdata source=daemon level=info tid=1 msg="NETDATA STARTUP: in 1162 ms, collecting system info - next: initialize RRD structures"
time=2024-10-16T09:07:55.347+00:00 comm=netdata source=daemon level=info tid=1 msg="SQLite database /var/cache/netdata/netdata-meta.db initialization"
time=2024-10-16T09:07:55.388+00:00 comm=netdata source=daemon level=info tid=1 msg="metadata database version is 18 (no migration needed)"
time=2024-10-16T09:07:55.621+00:00 comm=netdata source=daemon level=info tid=1 msg="SQLite database initialization completed"
time=2024-10-16T09:07:55.623+00:00 comm=netdata source=daemon level=info tid=1 msg="SQLite database /var/cache/netdata/context-meta.db initialization"
time=2024-10-16T09:07:55.664+00:00 comm=netdata source=daemon level=info tid=1 msg="context database version is 1 (no migration needed)"
time=2024-10-16T09:07:55.723+00:00 comm=netdata source=daemon level=info tid=165 thread=DBENGINIT[0] msg="DBENGINE: found 5 files in path /var/cache/netdata/dbengine"
time=2024-10-16T09:07:55.723+00:00 comm=netdata source=daemon level=info tid=165 thread=DBENGINIT[0] msg="DBENGINE: loading 2 data/journal of tier 0..."
time=2024-10-16T09:07:55.724+00:00 comm=netdata source=daemon level=info tid=167 thread=DBENGINIT[1] msg="DBENGINE: found 0 files in path /var/cache/netdata/dbengine-tier1"
time=2024-10-16T09:07:55.724+00:00 comm=netdata source=daemon level=info tid=167 thread=DBENGINIT[1] msg="DBENGINE: data files not found, creating in path \"/var/cache/netdata/dbengine-tier1\"."
time=2024-10-16T09:07:55.724+00:00 comm=netdata source=daemon level=info tid=168 thread=DBENGINIT[2] msg="DBENGINE: found 0 files in path /var/cache/netdata/dbengine-tier2"
time=2024-10-16T09:07:55.724+00:00 comm=netdata source=daemon level=info tid=168 thread=DBENGINIT[2] msg="DBENGINE: data files not found, creating in path \"/var/cache/netdata/dbengine-tier2\"."
time=2024-10-16T09:07:55.726+00:00 comm=netdata source=daemon level=info tid=168 thread=DBENGINIT[2] msg="DBENGINE: created data file \"/var/cache/netdata/dbengine-tier2/datafile-1-0000000001.ndf\"."
time=2024-10-16T09:07:55.726+00:00 comm=netdata source=daemon level=error tid=165 thread=DBENGINIT[0] msg="Invalid file /var/cache/netdata/dbengine/journalfile-1-0000000001.njfv2. Not the expected size"
time=2024-10-16T09:07:55.728+00:00 comm=netdata source=daemon level=info tid=168 thread=DBENGINIT[2] msg="DBENGINE: created journal file \"/var/cache/netdata/dbengine-tier2/journalfile-1-0000000001.njf\"."
time=2024-10-16T09:07:55.728+00:00 comm=netdata source=daemon level=info tid=168 thread=DBENGINIT[2] msg="DBENGINE: populating retention to MRG from 1 journal files of tier 2, using 1 threads..."
time=2024-10-16T09:07:55.819+00:00 comm=netdata source=daemon level=info tid=167 thread=DBENGINIT[1] msg="DBENGINE: created data file \"/var/cache/netdata/dbengine-tier1/datafile-1-0000000001.ndf\"."
time=2024-10-16T09:07:55.821+00:00 comm=netdata source=daemon level=info tid=167 thread=DBENGINIT[1] msg="DBENGINE: created journal file \"/var/cache/netdata/dbengine-tier1/journalfile-1-0000000001.njf\"."
time=2024-10-16T09:07:55.821+00:00 comm=netdata source=daemon level=info tid=167 thread=DBENGINIT[1] msg="DBENGINE: populating retention to MRG from 1 journal files of tier 1, using 1 threads..."
time=2024-10-16T09:07:56.273+00:00 comm=netdata source=daemon level=info tid=165 thread=DBENGINIT[0] msg="DBENGINE: indexing file '/var/cache/netdata/dbengine/journalfile-1-0000000001.njfv2': extents 1098, metrics 28994, pages 70272"
time=2024-10-16T09:07:56.273+00:00 comm=netdata source=daemon level=error errno="1, Operation not permitted" tid=165 thread=DBENGINIT[0] msg="Cannot create/open file '/var/cache/netdata/dbengine/journalfile-1-0000000001.njfv2'."
I tried a different approach for the Netdata parent I moved away from the CSI NFS Driver and used the Hostpath Storage approach starting from Customized directory used for PersistentVolume method which can be found here
My configuration for Netdata persistence looks like the following now which I thought had fixed the issue but then after a period of time the dreaded chown error returned. In the below content I have left the CSI NFS Driver configuration for Netdata to show both methods.
Update
This has finally been fixed with the lucky 777 permissions, I think. I also suggested to Netdata to allow us to force the permissions using something like this in the Netdata Helm Chart. I made an issue for Netdata here
volumePermissions:
## @param netdata.volumePermissions.enabled Enable init container that changes the owner and group of the persistent volume(s) mountpoint to `runAsUser:fsGroup`
##
enabled: true
## @param netdata.volumePermissions.image.tag Init container volume-permissions image tag (immutable tags are recommended)
# netdata-manifest.yaml which is stored in the Gimlet directory manifests
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: pi8s-nfs-netdata
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: microk8s.io/hostpath
volumeBindingMode: Immediate
allowVolumeExpansion: true
reclaimPolicy: Retain
parameters:
pvDir: "/mnt/pi8s/netdata"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pi8s-netdata-pvc
namespace: infrastructure
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: "pi8s-nfs-netdata"
Mount Permissions
0 (Default)
- This disables the automatic permission setting for the volume directory.
- It means the NFS CSI driver will not attempt to modify the permissions of the directory upon mounting. The permissions will remain as they are on the NFS server.
- This can be useful if the NFS server already has the desired permissions configured, or if you want to manage permissions manually.
755
- Read and execute access for everyone, and write access only for the owner (rwxr-xr-x).
- Commonly used for directories where the owner needs write access, but group and others only need to read or execute (e.g., for shared applications or read-only access).
777
- Full read, write, and execute access for everyone (rwxrwxrwx).
- This makes the directory fully open to all users. Use with caution, as it can pose security risks if sensitive data is being accessed.
644
- Read and write access for the owner, and read-only access for group and others (rw-r–r–).
- Useful for files or directories where you want to ensure the owner can modify the files, but others can only view them.
600
- Read and write access only for the owner (rw——-).
- This setting is for more secure or sensitive directories where only the owner should have any access, and no permissions are granted to group or others.
700
- Full access only for the owner (rwx——).
- The owner has full permissions (read, write, execute), and no permissions are granted to group or others. This is useful for private data that should not be accessible to others.
Here is what my persistent volumes, persistent volume claims and storage classes look like now:
kubectl get pv,pvc,sc
# Persistent Volumes
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
persistentvolume/pvc-081130cf-1a18-466f-a970-e518dcc4e6e3 1Gi RWO Retain Bound infrastructure/netdata-parent-alarms pi8s-nfs-netdata <unset> 65m
persistentvolume/pvc-142f3b3c-cddd-4ba7-80a4-c43f28f8cf18 5Gi RWO Retain Bound infrastructure/netdata-parent-database pi8s-nfs-netdata <unset> 65m
persistentvolume/pvc-43ff5e15-c055-4258-97f5-fa2e6b7768fd 8Gi RWO Retain Bound infrastructure/localstack nfs-csi-localstack <unset> 3d12h
persistentvolume/pvc-8543d912-e516-40cd-afde-a4eeaec02fd4 8Gi RWO Retain Bound infrastructure/jenkins nfs-csi-jenkins <unset> 27d
persistentvolume/pvc-cb68ce51-ac01-44ce-992e-60e638cdafd7 10Gi RWX Retain Bound infrastructure/pi8s-netdata-pvc pi8s-nfs-netdata <unset> 56m
persistentvolume/pvc-e4b42d10-b4d2-4996-906f-4f868006ac4c 1Gi RWO Retain Bound infrastructure/netdata-k8s-state-varlib pi8s-nfs-netdata <unset> 65m
persistentvolume/pvc-e92ddd38-5f02-493e-b5bd-3b7728ab3fd4 128Mi RWO Retain Bound infrastructure/traefik nfs-csi-traefik <unset>
# Persistent Volume Claims
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
persistentvolumeclaim/jenkins Bound pvc-8543d912-e516-40cd-afde-a4eeaec02fd4 8Gi RWO nfs-csi-jenkins <unset> 27d
persistentvolumeclaim/localstack Bound pvc-43ff5e15-c055-4258-97f5-fa2e6b7768fd 8Gi RWO nfs-csi-localstack <unset> 3d12h
persistentvolumeclaim/netdata-k8s-state-varlib Bound pvc-e4b42d10-b4d2-4996-906f-4f868006ac4c 1Gi RWO pi8s-nfs-netdata <unset> 65m
persistentvolumeclaim/netdata-parent-alarms Bound pvc-081130cf-1a18-466f-a970-e518dcc4e6e3 1Gi RWO pi8s-nfs-netdata <unset> 65m
persistentvolumeclaim/netdata-parent-database Bound pvc-142f3b3c-cddd-4ba7-80a4-c43f28f8cf18 5Gi RWO pi8s-nfs-netdata <unset> 65m
persistentvolumeclaim/pi8s-netdata-pvc Bound pvc-cb68ce51-ac01-44ce-992e-60e638cdafd7 10Gi RWX pi8s-nfs-netdata <unset> 56m
persistentvolumeclaim/traefik Bound pvc-e92ddd38-5f02-493e-b5bd-3b7728ab3fd4 128Mi RWO nfs-csi-traefik <unset> 27d
# Storage Classes
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/nfs-csi-jenkins nfs.csi.k8s.io Retain Immediate true 27d
storageclass.storage.k8s.io/nfs-csi-localstack nfs.csi.k8s.io Retain Immediate true 27d
storageclass.storage.k8s.io/nfs-csi-traefik nfs.csi.k8s.io Retain Immediate true 27d
storageclass.storage.k8s.io/pi8s-nfs-netdata (default) microk8s.io/hostpath Retain Immediate true 86m
---
apiVersion: helm.toolkit.fluxcd.io/v2beta2
kind: HelmRelease
metadata:
name: csi-driver-nfs
namespace: kube-system
spec:
interval: 60m
releaseName: csi-driver-nfs
chart:
spec:
chart: csi-driver-nfs
version: v4.9.0
sourceRef:
kind: HelmRepository
name: csi-driver-nfs
interval: 10m
values:
customLabels: {}
image:
baseRepo: registry.k8s.io
nfs:
repository: registry.k8s.io/sig-storage/nfsplugin
tag: v4.9.0
pullPolicy: IfNotPresent
csiProvisioner:
repository: registry.k8s.io/sig-storage/csi-provisioner
tag: v5.0.2
pullPolicy: IfNotPresent
csiSnapshotter:
repository: registry.k8s.io/sig-storage/csi-snapshotter
tag: v8.0.1
pullPolicy: IfNotPresent
livenessProbe:
repository: registry.k8s.io/sig-storage/livenessprobe
tag: v2.13.1
pullPolicy: IfNotPresent
nodeDriverRegistrar:
repository: registry.k8s.io/sig-storage/csi-node-driver-registrar
tag: v2.11.1
pullPolicy: IfNotPresent
externalSnapshotter:
repository: registry.k8s.io/sig-storage/snapshot-controller
tag: v8.0.1
pullPolicy: IfNotPresent
serviceAccount:
create: true # When true, service accounts will be created for you. Set to false if you want to use your own.
controller: csi-nfs-controller-sa # Name of Service Account to be created or used
node: csi-nfs-node-sa # Name of Service Account to be created or used
rbac:
create: true
name: nfs
driver:
name: nfs.csi.k8s.io
mountPermissions: 0
feature:
enableFSGroupPolicy: true
enableInlineVolume: false
propagateHostMountOptions: false
#kubeletDir: /var/lib/kubelet # default config
kubeletDir: "/var/snap/microk8s/common/var/lib/kubelet" # Specific for microk8s
controller:
name: csi-nfs-controller
replicas: 3
strategyType: Recreate
runOnMaster: false
runOnControlPlane: false
livenessProbe:
healthPort: 29652
logLevel: 5
workingMountDir: /tmp
dnsPolicy: ClusterFirstWithHostNet # available values: Default, ClusterFirstWithHostNet, ClusterFirst
defaultOnDeletePolicy: delete # available values: delete, retain
affinity: {}
nodeSelector: {}
priorityClassName: system-cluster-critical
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/controlplane"
operator: "Exists"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
resources:
csiProvisioner:
limits:
memory: 400Mi
requests:
cpu: 10m
memory: 20Mi
csiSnapshotter:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 20Mi
livenessProbe:
limits:
memory: 100Mi
requests:
cpu: 10m
memory: 20Mi
nfs:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 20Mi
node:
name: csi-nfs-node
dnsPolicy: ClusterFirstWithHostNet # available values: Default, ClusterFirstWithHostNet, ClusterFirst
maxUnavailable: 1
logLevel: 5
livenessProbe:
healthPort: 29653
affinity: {}
nodeSelector: {}
priorityClassName: system-cluster-critical
tolerations:
- operator: "Exists"
resources:
livenessProbe:
limits:
memory: 100Mi
requests:
cpu: 10m
memory: 20Mi
nodeDriverRegistrar:
limits:
memory: 100Mi
requests:
cpu: 10m
memory: 20Mi
nfs:
limits:
memory: 300Mi
requests:
cpu: 10m
memory: 20Mi
externalSnapshotter:
enabled: true
name: snapshot-controller
priorityClassName: system-cluster-critical
controller:
replicas: 3
resources:
limits:
memory: 300Mi
requests:
cpu: 10m
memory: 20Mi
# Create volume snapshot CRDs.
customResourceDefinitions:
enabled: true #if set true, VolumeSnapshot, VolumeSnapshotContent and VolumeSnapshotClass CRDs will be created. Set it false, If they already exist in cluster.
## Reference to one or more secrets to be used when pulling images
## ref: https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
##
imagePullSecrets: []
# - name: "image-pull-secret"
## StorageClass resource example:
storageClass:
create: false
# name: nfs-csi
# annotations:
# storageclass.kubernetes.io/is-default-class: "true"
# parameters:
# server: nfs-server.default.svc.cluster.local
# share: /
# subDir:
# mountPermissions: "0"
# csi.storage.k8s.io/provisioner-secret is only needed for providing mountOptions in DeleteVolume
# csi.storage.k8s.io/provisioner-secret-name: "mount-options"
# csi.storage.k8s.io/provisioner-secret-namespace: "default"
# reclaimPolicy: Delete
# volumeBindingMode: Immediate
# mountOptions:
# - nfsvers=4.1
- Create a file in your Gimlet GitOps infra repo in
manifests/calledcsi-nfs-storage-classes.yamland paste the yaml below - Gimlet will pickup any Kubernetes manifests you create in the
manifestsdirectory and deploy them for you
---
# StorageClass for netdata which I am leaving here as an example for configuring netdata using the CSI driver
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi-netdata
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.152 # Replace with your NFS server IP or FQDN
share: /volume4/pi8s/ # Replace with your NFS volume share
subDir: netdata
mountPermissions: "700" # The owner has full permissions (read, write, execute), and no permissions are granted to group or others
csi.storage.k8s.io/fstype: "nfs4" # Optional parameter for file system type
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
mountOptions:
- nfsvers=4
- hard
---
# StorageClass for traefik
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi-traefik
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.152 # Replace with your NFS server IP or FQDN
share: /volume4/pi8s/ # Replace with your NFS volume share
subDir: traefik
mountPermissions: "0"
csi.storage.k8s.io/fstype: "nfs4" # Optional parameter for file system type
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
mountOptions:
- nfsvers=4
- hard
---
# StorageClass for jenkins
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi-jenkins
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.152 # Replace with your NFS server IP or FQDN
share: /volume4/pi8s/ # Replace with your NFS volume share
subDir: jenkins
mountPermissions: "0"
csi.storage.k8s.io/fstype: "nfs4" # Optional parameter for file system type
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
mountOptions:
- nfsvers=4
- hard
---
# StorageClass for localstack
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi-localstack
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.152 # Replace with your NFS server IP or FQDN
share: /volume4/pi8s/ # Replace with your NFS volume share
subDir: localstack
mountPermissions: "0"
csi.storage.k8s.io/fstype: "nfs4" # Optional parameter for file system type
reclaimPolicy: Retain
volumeBindingMode: Immediate
allowVolumeExpansion: true
mountOptions:
- nfsvers=4
- hard
- Lets git it
git add .
git commit -m "k8s infra csi nfs driver deploy"
git push
Fluxcd is doing the following under the hood | CSI NFS Driver
- Helm repo add
helm repo add csi-driver-nfs https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts --force-update
- Helm repo install
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs --namespace kube-system --version v4.8.0 \
--set controller.dnsPolicy=ClusterFirstWithHostNet \
--set node.dnsPolicy=ClusterFirstWithHostNet \
--set kubeletDir="/var/snap/microk8s/common/var/lib/kubelet"
Kubernetes check | CSI NFS Driver
- Kubectl switch to the
kube-systemnamespace
kubectl config set-context --current --namespace=kube-system
- Kubectl show me the pods
kubectl get pods -n kube-system

- Kubectl show me the Storage Class
# In this image the Netdata storage class is being deployed using the CSI NFS Driver
kubectl get sc --all-namespaces

- From CSI NFS Driver version v4.8.0 you no longer have to manually set the default Storage Class as there is an annotation provided
annotations:
storageclass.kubernetes.io/is-default-class: "true" # True for default, false for not the default
- Manually setting and unsetting the default Storage Class
kubectl -n kube-system patch storageclass nfs-csi -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
kubectl -n kube-system patch storageclass nfs-csi -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
Now you will be able to edit any values where you see the Storage Class value whether its an infrastructure deployment or an application deployment and have Kubernetes take care of centralising the storage on the NFS server in this case the Synology NAS.
Here are some examples.
- Traefik
persistence:
# -- Enable persistence using Persistent Volume Claims
# ref: http://kubernetes.io/docs/user-guide/persistent-volumes/
# It can be used to store TLS certificates, see `storage` in certResolvers
enabled: true
name: data
# existingClaim: ""
accessMode: ReadWriteOnce
size: 128Mi
storageClass: "nfs-csi-traefik"
# volumeName: ""
path: /data
annotations: {}
# -- Only mount a subpath of the Volume into the pod
# subPath: ""
- Netdata
persistence:
enabled: true
## Set '-' as the storageclass to get a volume from the default storage class.
storageclass: "nfs-csi-netdata"
volumesize: 1Gi
Great we now have Kubernetes managing NFS volume mounts dynamically!
Kubernetes Cert Manager Deployment
With Cert Manager we will manage all our certificate needs.
- Cert Manager Github repo
- Kubectl quick reference here
- Helm cheat sheet here
- Helm Chart reference here
- What Is SSL? How Do SSL Certificates Work?
Helm-Repository | Cert Manager
- Lets add the Kubernetes Cert Manager Helm repository
- A Helm repository is a collection of Helm charts that are made available for download and installation
- Helm repositories serve as centralised locations where Helm charts can be stored, shared, and managed
- Create a file called
certman.yamlin thehelm-repositoriesdirectory and paste the following YAML
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: cert-manager
namespace: kube-system
spec:
interval: 60m
url: https://charts.jetstack.io
Helm-Release | Cert Manager
- Lets create a Helm release of the Kubernetes Cert Manager
- A Helm release is an instance of a Helm chart running in a Kubernetes cluster
- Each release is a deployment of a particular version of a chart with a specific configuration
- Create a file called
certman.yamlin thehelm-releasesdirectory and paste the following YAML
Helm Chart Configuration Highlights
- You may want to edit these to suit your environment
crds:
# This option decides if the CRDs should be installed
# as part of the Helm installation.
enabled: true
replicaCount: 3
webhook:
# Number of replicas of the cert-manager webhook to run.
#
# The default is 1, but in production set this to 2 or 3 to provide high
# availability.
#
# If `replicas > 1`, consider setting `webhook.podDisruptionBudget.enabled=true`.
replicaCount: 3
cainjector:
# Create the CA Injector deployment
enabled: true
# The number of replicas of the cert-manager cainjector to run.
#
# The default is 1, but in production set this to 2 or 3 to provide high
# availability.
#
# If `replicas > 1`, consider setting `cainjector.podDisruptionBudget.enabled=true`.
#
# Note that cert-manager uses leader election to ensure that there can
# only be a single instance active at a time.
replicaCount: 3
apiVersion: helm.toolkit.fluxcd.io/v2beta2
kind: HelmRelease
metadata:
name: cert-manager
namespace: kube-system
spec:
interval: 60m
releaseName: cert-manager
chart:
spec:
chart: cert-manager
version: v1.15.1 # Simply change the version to upgrade
sourceRef:
kind: HelmRepository
name: external
interval: 10m
# values: Your values go here to override the default values
values:
# +docs:section=Global
# Default values for cert-manager.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
global:
# Reference to one or more secrets to be used when pulling images.
# For more information, see [Pull an Image from a Private Registry](https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/).
#
# For example:
# imagePullSecrets:
# - name: "image-pull-secret"
imagePullSecrets: []
# Labels to apply to all resources.
# Please note that this does not add labels to the resources created dynamically by the controllers.
# For these resources, you have to add the labels in the template in the cert-manager custom resource:
# For example, podTemplate/ ingressTemplate in ACMEChallengeSolverHTTP01Ingress
# For more information, see the [cert-manager documentation](https://cert-manager.io/docs/reference/api-docs/#acme.cert-manager.io/v1.ACMEChallengeSolverHTTP01Ingress).
# For example, secretTemplate in CertificateSpec
# For more information, see the [cert-manager documentation](https://cert-manager.io/docs/reference/api-docs/#cert-manager.io/v1.CertificateSpec).
commonLabels: {}
# The number of old ReplicaSets to retain to allow rollback (if not set, the default Kubernetes value is set to 10).
# +docs:property
# revisionHistoryLimit: 1
# The optional priority class to be used for the cert-manager pods.
priorityClassName: ""
rbac:
# Create required ClusterRoles and ClusterRoleBindings for cert-manager.
create: true
# Aggregate ClusterRoles to Kubernetes default user-facing roles. For more information, see [User-facing roles](https://kubernetes.io/docs/reference/access-authn-authz/rbac/#user-facing-roles)
aggregateClusterRoles: true
podSecurityPolicy:
# Create PodSecurityPolicy for cert-manager.
#
# Note that PodSecurityPolicy was deprecated in Kubernetes 1.21 and removed in Kubernetes 1.25.
enabled: false
# Configure the PodSecurityPolicy to use AppArmor.
useAppArmor: true
# Set the verbosity of cert-manager. A range of 0 - 6, with 6 being the most verbose.
logLevel: 2
leaderElection:
# Override the namespace used for the leader election lease.
namespace: "kube-system"
# The duration that non-leader candidates will wait after observing a
# leadership renewal until attempting to acquire leadership of a led but
# unrenewed leader slot. This is effectively the maximum duration that a
# leader can be stopped before it is replaced by another candidate.
# +docs:property
# leaseDuration: 60s
# The interval between attempts by the acting master to renew a leadership
# slot before it stops leading. This must be less than or equal to the
# lease duration.
# +docs:property
# renewDeadline: 40s
# The duration the clients should wait between attempting acquisition and
# renewal of a leadership.
# +docs:property
# retryPeriod: 15s
# This option is equivalent to setting crds.enabled=true and crds.keep=true.
# Deprecated: use crds.enabled and crds.keep instead.
installCRDs: false
crds:
# This option decides if the CRDs should be installed
# as part of the Helm installation.
enabled: true
# This option makes it so that the "helm.sh/resource-policy": keep
# annotation is added to the CRD. This will prevent Helm from uninstalling
# the CRD when the Helm release is uninstalled.
# WARNING: when the CRDs are removed, all cert-manager custom resources
# (Certificates, Issuers, ...) will be removed too by the garbage collector.
keep: true
# +docs:section=Controller
# The number of replicas of the cert-manager controller to run.
#
# The default is 1, but in production set this to 2 or 3 to provide high
# availability.
#
# If `replicas > 1`, consider setting `podDisruptionBudget.enabled=true`.
#
# Note that cert-manager uses leader election to ensure that there can
# only be a single instance active at a time.
replicaCount: 3
# Deployment update strategy for the cert-manager controller deployment.
# For more information, see the [Kubernetes documentation](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#strategy).
#
# For example:
# strategy:
# type: RollingUpdate
# rollingUpdate:
# maxSurge: 0
# maxUnavailable: 1
strategy: {}
podDisruptionBudget:
# Enable or disable the PodDisruptionBudget resource.
#
# This prevents downtime during voluntary disruptions such as during a Node upgrade.
# For example, the PodDisruptionBudget will block `kubectl drain`
# if it is used on the Node where the only remaining cert-manager
# Pod is currently running.
enabled: false
# This configures the minimum available pods for disruptions. It can either be set to
# an integer (e.g. 1) or a percentage value (e.g. 25%).
# It cannot be used if `maxUnavailable` is set.
# +docs:property
# minAvailable: 1
# This configures the maximum unavailable pods for disruptions. It can either be set to
# an integer (e.g. 1) or a percentage value (e.g. 25%).
# it cannot be used if `minAvailable` is set.
# +docs:property
# maxUnavailable: 1
# A comma-separated list of feature gates that should be enabled on the
# controller pod.
featureGates: ""
# The maximum number of challenges that can be scheduled as 'processing' at once.
maxConcurrentChallenges: 60
image:
# The container registry to pull the manager image from.
# +docs:property
# registry: quay.io
# The container image for the cert-manager controller.
# +docs:property
repository: quay.io/jetstack/cert-manager-controller
# Override the image tag to deploy by setting this variable.
# If no value is set, the chart's appVersion is used.
# +docs:property
# tag: vX.Y.Z
# Setting a digest will override any tag.
# +docs:property
# digest: sha256:0e072dddd1f7f8fc8909a2ca6f65e76c5f0d2fcfb8be47935ae3457e8bbceb20
# Kubernetes imagePullPolicy on Deployment.
pullPolicy: IfNotPresent
# Override the namespace used to store DNS provider credentials etc. for ClusterIssuer
# resources. By default, the same namespace as cert-manager is deployed within is
# used. This namespace will not be automatically created by the Helm chart.
clusterResourceNamespace: ""
# This namespace allows you to define where the services are installed into.
# If not set then they use the namespace of the release.
# This is helpful when installing cert manager as a chart dependency (sub chart).
namespace: ""
serviceAccount:
# Specifies whether a service account should be created.
create: true
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template.
# +docs:property
# name: ""
# Optional additional annotations to add to the controller's Service Account.
# +docs:property
# annotations: {}
# Optional additional labels to add to the controller's Service Account.
# +docs:property
# labels: {}
# Automount API credentials for a Service Account.
automountServiceAccountToken: true
# Automounting API credentials for a particular pod.
# +docs:property
# automountServiceAccountToken: true
# When this flag is enabled, secrets will be automatically removed when the certificate resource is deleted.
enableCertificateOwnerRef: false
# This property is used to configure options for the controller pod.
# This allows setting options that would usually be provided using flags.
# An APIVersion and Kind must be specified in your values.yaml file.
# Flags will override options that are set here.
#
# For example:
# config:
# apiVersion: controller.config.cert-manager.io/v1alpha1
# kind: ControllerConfiguration
# logging:
# verbosity: 2
# format: text
# leaderElectionConfig:
# namespace: kube-system
# kubernetesAPIQPS: 9000
# kubernetesAPIBurst: 9000
# numberOfConcurrentWorkers: 200
# featureGates:
# AdditionalCertificateOutputFormats: true
# DisallowInsecureCSRUsageDefinition: true
# ExperimentalCertificateSigningRequestControllers: true
# ExperimentalGatewayAPISupport: true
# LiteralCertificateSubject: true
# SecretsFilteredCaching: true
# ServerSideApply: true
# StableCertificateRequestName: true
# UseCertificateRequestBasicConstraints: true
# ValidateCAA: true
# metricsTLSConfig:
# dynamic:
# secretNamespace: "cert-manager"
# secretName: "cert-manager-metrics-ca"
# dnsNames:
# - cert-manager-metrics
# - cert-manager-metrics.cert-manager
# - cert-manager-metrics.cert-manager.svc
config: {}
# Setting Nameservers for DNS01 Self Check.
# For more information, see the [cert-manager documentation](https://cert-manager.io/docs/configuration/acme/dns01/#setting-nameservers-for-dns01-self-check).
# A comma-separated string with the host and port of the recursive nameservers cert-manager should query.
dns01RecursiveNameservers: ""
# Forces cert-manager to use only the recursive nameservers for verification.
# Enabling this option could cause the DNS01 self check to take longer owing to caching performed by the recursive nameservers.
dns01RecursiveNameserversOnly: false
# Option to disable cert-manager's build-in auto-approver. The auto-approver
# approves all CertificateRequests that reference issuers matching the 'approveSignerNames'
# option. This 'disableAutoApproval' option is useful when you want to make all approval decisions
# using a different approver (like approver-policy - https://github.com/cert-manager/approver-policy).
disableAutoApproval: false
# List of signer names that cert-manager will approve by default. CertificateRequests
# referencing these signer names will be auto-approved by cert-manager. Defaults to just
# approving the cert-manager.io Issuer and ClusterIssuer issuers. When set to an empty
# array, ALL issuers will be auto-approved by cert-manager. To disable the auto-approval,
# because eg. you are using approver-policy, you can enable 'disableAutoApproval'.
# ref: https://cert-manager.io/docs/concepts/certificaterequest/#approval
# +docs:property
approveSignerNames:
- issuers.cert-manager.io/*
- clusterissuers.cert-manager.io/*
# Additional command line flags to pass to cert-manager controller binary.
# To see all available flags run `docker run quay.io/jetstack/cert-manager-controller:<version> --help`.
#
# Use this flag to enable or disable arbitrary controllers. For example, to disable the CertificiateRequests approver.
#
# For example:
# extraArgs:
# - --controllers=*,-certificaterequests-approver
extraArgs: []
# Additional environment variables to pass to cert-manager controller binary.
extraEnv: []
# - name: SOME_VAR
# value: 'some value'
# Resources to provide to the cert-manager controller pod.
#
# For example:
# requests:
# cpu: 10m
# memory: 32Mi
#
# For more information, see [Resource Management for Pods and Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
resources: {}
# Pod Security Context.
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
# Container Security Context to be set on the controller component container.
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
containerSecurityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
# Additional volumes to add to the cert-manager controller pod.
volumes: []
# Additional volume mounts to add to the cert-manager controller container.
volumeMounts: []
# Optional additional annotations to add to the controller Deployment.
# +docs:property
# deploymentAnnotations: {}
# Optional additional annotations to add to the controller Pods.
# +docs:property
# podAnnotations: {}
# Optional additional labels to add to the controller Pods.
podLabels: {}
# Optional annotations to add to the controller Service.
# +docs:property
# serviceAnnotations: {}
# Optional additional labels to add to the controller Service.
# +docs:property
# serviceLabels: {}
# Optionally set the IP family policy for the controller Service to configure dual-stack; see [Configure dual-stack](https://kubernetes.io/docs/concepts/services-networking/dual-stack/#services).
# +docs:property
# serviceIPFamilyPolicy: ""
# Optionally set the IP families for the controller Service that should be supported, in the order in which they should be applied to ClusterIP. Can be IPv4 and/or IPv6.
# +docs:property
# serviceIPFamilies: []
# Optional DNS settings. These are useful if you have a public and private DNS zone for
# the same domain on Route 53. The following is an example of ensuring
# cert-manager can access an ingress or DNS TXT records at all times.
# Note that this requires Kubernetes 1.10 or `CustomPodDNS` feature gate enabled for
# the cluster to work.
# Pod DNS policy.
# For more information, see [Pod's DNS Policy](https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#pod-s-dns-policy).
# +docs:property
# podDnsPolicy: "None"
# Pod DNS configuration. The podDnsConfig field is optional and can work with any podDnsPolicy
# settings. However, when a Pod's dnsPolicy is set to "None", the dnsConfig field has to be specified.
# For more information, see [Pod's DNS Config](https://kubernetes.io/docs/concepts/services-networking/dns-pod-service/#pod-dns-config).
# +docs:property
# podDnsConfig:
# nameservers:
# - "1.1.1.1"
# - "8.8.8.8"
# Optional hostAliases for cert-manager-controller pods. May be useful when performing ACME DNS-01 self checks.
hostAliases: []
# - ip: 127.0.0.1
# hostnames:
# - foo.local
# - bar.local
# - ip: 10.1.2.3
# hostnames:
# - foo.remote
# - bar.remote
# The nodeSelector on Pods tells Kubernetes to schedule Pods on the nodes with
# matching labels.
# For more information, see [Assigning Pods to Nodes](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/).
#
# This default ensures that Pods are only scheduled to Linux nodes.
# It prevents Pods being scheduled to Windows nodes in a mixed OS cluster.
# +docs:property
nodeSelector:
kubernetes.io/os: linux
# +docs:ignore
ingressShim:
{}
# Optional default issuer to use for ingress resources.
# +docs:property=ingressShim.defaultIssuerName
# defaultIssuerName: ""
# Optional default issuer kind to use for ingress resources.
# +docs:property=ingressShim.defaultIssuerKind
# defaultIssuerKind: ""
# Optional default issuer group to use for ingress resources.
# +docs:property=ingressShim.defaultIssuerGroup
# defaultIssuerGroup: ""
# Use these variables to configure the HTTP_PROXY environment variables.
# Configures the HTTP_PROXY environment variable where a HTTP proxy is required.
# +docs:property
# http_proxy: "http://proxy:8080"
# Configures the HTTPS_PROXY environment variable where a HTTP proxy is required.
# +docs:property
# https_proxy: "https://proxy:8080"
# Configures the NO_PROXY environment variable where a HTTP proxy is required,
# but certain domains should be excluded.
# +docs:property
# no_proxy: 127.0.0.1,localhost
# A Kubernetes Affinity, if required. For more information, see [Affinity v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#affinity-v1-core).
#
# For example:
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: foo.bar.com/role
# operator: In
# values:
# - master
affinity: {}
# A list of Kubernetes Tolerations, if required. For more information, see [Toleration v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#toleration-v1-core).
#
# For example:
# tolerations:
# - key: foo.bar.com/role
# operator: Equal
# value: master
# effect: NoSchedule
tolerations: []
# A list of Kubernetes TopologySpreadConstraints, if required. For more information, see [Topology spread constraint v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#topologyspreadconstraint-v1-core
#
# For example:
# topologySpreadConstraints:
# - maxSkew: 2
# topologyKey: topology.kubernetes.io/zone
# whenUnsatisfiable: ScheduleAnyway
# labelSelector:
# matchLabels:
# app.kubernetes.io/instance: cert-manager
# app.kubernetes.io/component: controller
topologySpreadConstraints: []
# LivenessProbe settings for the controller container of the controller Pod.
#
# This is enabled by default, in order to enable the clock-skew liveness probe that
# restarts the controller in case of a skew between the system clock and the monotonic clock.
# LivenessProbe durations and thresholds are based on those used for the Kubernetes
# controller-manager. For more information see the following on the
# [Kubernetes GitHub repository](https://github.com/kubernetes/kubernetes/blob/806b30170c61a38fedd54cc9ede4cd6275a1ad3b/cmd/kubeadm/app/util/staticpod/utils.go#L241-L245)
# +docs:property
livenessProbe:
enabled: true
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 15
successThreshold: 1
failureThreshold: 8
# enableServiceLinks indicates whether information about services should be
# injected into the pod's environment variables, matching the syntax of Docker
# links.
enableServiceLinks: false
# +docs:section=Prometheus
prometheus:
# Enable Prometheus monitoring for the cert-manager controller to use with the
# Prometheus Operator. If this option is enabled without enabling `prometheus.servicemonitor.enabled` or
# `prometheus.podmonitor.enabled`, 'prometheus.io' annotations are added to the cert-manager Deployment
# resources. Additionally, a service is created which can be used together
# with your own ServiceMonitor (managed outside of this Helm chart).
# Otherwise, a ServiceMonitor/ PodMonitor is created.
enabled: true
servicemonitor:
# Create a ServiceMonitor to add cert-manager to Prometheus.
enabled: false
# Specifies the `prometheus` label on the created ServiceMonitor. This is
# used when different Prometheus instances have label selectors matching
# different ServiceMonitors.
prometheusInstance: default
# The target port to set on the ServiceMonitor. This must match the port that the
# cert-manager controller is listening on for metrics.
targetPort: 9402
# The path to scrape for metrics.
path: /metrics
# The interval to scrape metrics.
interval: 60s
# The timeout before a metrics scrape fails.
scrapeTimeout: 30s
# Additional labels to add to the ServiceMonitor.
labels: {}
# Additional annotations to add to the ServiceMonitor.
annotations: {}
# Keep labels from scraped data, overriding server-side labels.
honorLabels: false
# EndpointAdditionalProperties allows setting additional properties on the
# endpoint such as relabelings, metricRelabelings etc.
#
# For example:
# endpointAdditionalProperties:
# relabelings:
# - action: replace
# sourceLabels:
# - __meta_kubernetes_pod_node_name
# targetLabel: instance
#
# +docs:property
endpointAdditionalProperties: {}
# Note that you can not enable both PodMonitor and ServiceMonitor as they are mutually exclusive. Enabling both will result in a error.
podmonitor:
# Create a PodMonitor to add cert-manager to Prometheus.
enabled: false
# Specifies the `prometheus` label on the created PodMonitor. This is
# used when different Prometheus instances have label selectors matching
# different PodMonitors.
prometheusInstance: default
# The path to scrape for metrics.
path: /metrics
# The interval to scrape metrics.
interval: 60s
# The timeout before a metrics scrape fails.
scrapeTimeout: 30s
# Additional labels to add to the PodMonitor.
labels: {}
# Additional annotations to add to the PodMonitor.
annotations: {}
# Keep labels from scraped data, overriding server-side labels.
honorLabels: false
# EndpointAdditionalProperties allows setting additional properties on the
# endpoint such as relabelings, metricRelabelings etc.
#
# For example:
# endpointAdditionalProperties:
# relabelings:
# - action: replace
# sourceLabels:
# - __meta_kubernetes_pod_node_name
# targetLabel: instance
#
# +docs:property
endpointAdditionalProperties: {}
# +docs:section=Webhook
webhook:
# Number of replicas of the cert-manager webhook to run.
#
# The default is 1, but in production set this to 2 or 3 to provide high
# availability.
#
# If `replicas > 1`, consider setting `webhook.podDisruptionBudget.enabled=true`.
replicaCount: 3
# The number of seconds the API server should wait for the webhook to respond before treating the call as a failure.
# The value must be between 1 and 30 seconds. For more information, see
# [Validating webhook configuration v1](https://kubernetes.io/docs/reference/kubernetes-api/extend-resources/validating-webhook-configuration-v1/).
#
# The default is set to the maximum value of 30 seconds as
# users sometimes report that the connection between the K8S API server and
# the cert-manager webhook server times out.
# If *this* timeout is reached, the error message will be "context deadline exceeded",
# which doesn't help the user diagnose what phase of the HTTPS connection timed out.
# For example, it could be during DNS resolution, TCP connection, TLS
# negotiation, HTTP negotiation, or slow HTTP response from the webhook
# server.
# By setting this timeout to its maximum value the underlying timeout error
# message has more chance of being returned to the end user.
timeoutSeconds: 30
# This is used to configure options for the webhook pod.
# This allows setting options that would usually be provided using flags.
# An APIVersion and Kind must be specified in your values.yaml file.
# Flags override options that are set here.
#
# For example:
# apiVersion: webhook.config.cert-manager.io/v1alpha1
# kind: WebhookConfiguration
# # The port that the webhook listens on for requests.
# # In GKE private clusters, by default Kubernetes apiservers are allowed to
# # talk to the cluster nodes only on 443 and 10250. Configuring
# # securePort: 10250 therefore will work out-of-the-box without needing to add firewall
# # rules or requiring NET_BIND_SERVICE capabilities to bind port numbers < 1000.
# # This should be uncommented and set as a default by the chart once
# # the apiVersion of WebhookConfiguration graduates beyond v1alpha1.
# securePort: 10250
config: {}
# The update strategy for the cert-manager webhook deployment.
# For more information, see the [Kubernetes documentation](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#strategy)
#
# For example:
# strategy:
# type: RollingUpdate
# rollingUpdate:
# maxSurge: 0
# maxUnavailable: 1
strategy: {}
# Pod Security Context to be set on the webhook component Pod.
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
# Container Security Context to be set on the webhook component container.
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
containerSecurityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
podDisruptionBudget:
# Enable or disable the PodDisruptionBudget resource.
#
# This prevents downtime during voluntary disruptions such as during a Node upgrade.
# For example, the PodDisruptionBudget will block `kubectl drain`
# if it is used on the Node where the only remaining cert-manager
# Pod is currently running.
enabled: false
# This property configures the minimum available pods for disruptions. Can either be set to
# an integer (e.g. 1) or a percentage value (e.g. 25%).
# It cannot be used if `maxUnavailable` is set.
# +docs:property
# minAvailable: 1
# This property configures the maximum unavailable pods for disruptions. Can either be set to
# an integer (e.g. 1) or a percentage value (e.g. 25%).
# It cannot be used if `minAvailable` is set.
# +docs:property
# maxUnavailable: 1
# Optional additional annotations to add to the webhook Deployment.
# +docs:property
# deploymentAnnotations: {}
# Optional additional annotations to add to the webhook Pods.
# +docs:property
# podAnnotations: {}
# Optional additional annotations to add to the webhook Service.
# +docs:property
# serviceAnnotations: {}
# Optional additional annotations to add to the webhook MutatingWebhookConfiguration.
# +docs:property
# mutatingWebhookConfigurationAnnotations: {}
# Optional additional annotations to add to the webhook ValidatingWebhookConfiguration.
# +docs:property
# validatingWebhookConfigurationAnnotations: {}
validatingWebhookConfiguration:
# Configure spec.namespaceSelector for validating webhooks.
# +docs:property
namespaceSelector:
matchExpressions:
- key: "cert-manager.io/disable-validation"
operator: "NotIn"
values:
- "true"
mutatingWebhookConfiguration:
# Configure spec.namespaceSelector for mutating webhooks.
# +docs:property
namespaceSelector: {}
# matchLabels:
# key: value
# matchExpressions:
# - key: kubernetes.io/metadata.name
# operator: NotIn
# values:
# - kube-system
# Additional command line flags to pass to cert-manager webhook binary.
# To see all available flags run `docker run quay.io/jetstack/cert-manager-webhook:<version> --help`.
extraArgs: []
# Path to a file containing a WebhookConfiguration object used to configure the webhook.
# - --config=<path-to-config-file>
# Comma separated list of feature gates that should be enabled on the
# webhook pod.
featureGates: ""
# Resources to provide to the cert-manager webhook pod.
#
# For example:
# requests:
# cpu: 10m
# memory: 32Mi
#
# For more information, see [Resource Management for Pods and Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
resources: {}
# Liveness probe values.
# For more information, see [Container probes](https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#container-probes).
#
# +docs:property
livenessProbe:
failureThreshold: 3
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
# Readiness probe values.
# For more information, see [Container probes](https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#container-probes).
#
# +docs:property
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
# The nodeSelector on Pods tells Kubernetes to schedule Pods on the nodes with
# matching labels.
# For more information, see [Assigning Pods to Nodes](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/).
#
# This default ensures that Pods are only scheduled to Linux nodes.
# It prevents Pods being scheduled to Windows nodes in a mixed OS cluster.
# +docs:property
nodeSelector:
kubernetes.io/os: linux
# A Kubernetes Affinity, if required. For more information, see [Affinity v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#affinity-v1-core).
#
# For example:
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: foo.bar.com/role
# operator: In
# values:
# - master
affinity: {}
# A list of Kubernetes Tolerations, if required. For more information, see [Toleration v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#toleration-v1-core).
#
# For example:
# tolerations:
# - key: foo.bar.com/role
# operator: Equal
# value: master
# effect: NoSchedule
tolerations: []
# A list of Kubernetes TopologySpreadConstraints, if required. For more information, see [Topology spread constraint v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#topologyspreadconstraint-v1-core).
#
# For example:
# topologySpreadConstraints:
# - maxSkew: 2
# topologyKey: topology.kubernetes.io/zone
# whenUnsatisfiable: ScheduleAnyway
# labelSelector:
# matchLabels:
# app.kubernetes.io/instance: cert-manager
# app.kubernetes.io/component: controller
topologySpreadConstraints: []
# Optional additional labels to add to the Webhook Pods.
podLabels: {}
# Optional additional labels to add to the Webhook Service.
serviceLabels: {}
# Optionally set the IP family policy for the controller Service to configure dual-stack; see [Configure dual-stack](https://kubernetes.io/docs/concepts/services-networking/dual-stack/#services).
serviceIPFamilyPolicy: ""
# Optionally set the IP families for the controller Service that should be supported, in the order in which they should be applied to ClusterIP. Can be IPv4 and/or IPv6.
serviceIPFamilies: []
image:
# The container registry to pull the webhook image from.
# +docs:property
# registry: quay.io
# The container image for the cert-manager webhook
# +docs:property
repository: quay.io/jetstack/cert-manager-webhook
# Override the image tag to deploy by setting this variable.
# If no value is set, the chart's appVersion will be used.
# +docs:property
# tag: vX.Y.Z
# Setting a digest will override any tag
# +docs:property
# digest: sha256:0e072dddd1f7f8fc8909a2ca6f65e76c5f0d2fcfb8be47935ae3457e8bbceb20
# Kubernetes imagePullPolicy on Deployment.
pullPolicy: IfNotPresent
serviceAccount:
# Specifies whether a service account should be created.
create: true
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template.
# +docs:property
# name: ""
# Optional additional annotations to add to the controller's Service Account.
# +docs:property
# annotations: {}
# Optional additional labels to add to the webhook's Service Account.
# +docs:property
# labels: {}
# Automount API credentials for a Service Account.
automountServiceAccountToken: true
# Automounting API credentials for a particular pod.
# +docs:property
# automountServiceAccountToken: true
# The port that the webhook listens on for requests.
# In GKE private clusters, by default Kubernetes apiservers are allowed to
# talk to the cluster nodes only on 443 and 10250. Configuring
# securePort: 10250, therefore will work out-of-the-box without needing to add firewall
# rules or requiring NET_BIND_SERVICE capabilities to bind port numbers <1000.
securePort: 10250
# Specifies if the webhook should be started in hostNetwork mode.
#
# Required for use in some managed kubernetes clusters (such as AWS EKS) with custom
# CNI (such as calico), because control-plane managed by AWS cannot communicate
# with pods' IP CIDR and admission webhooks are not working
#
# Since the default port for the webhook conflicts with kubelet on the host
# network, `webhook.securePort` should be changed to an available port if
# running in hostNetwork mode.
hostNetwork: false
# Specifies how the service should be handled. Useful if you want to expose the
# webhook outside of the cluster. In some cases, the control plane cannot
# reach internal services.
serviceType: ClusterIP
# Specify the load balancer IP for the created service.
# +docs:property
# loadBalancerIP: "10.10.10.10"
# Overrides the mutating webhook and validating webhook so they reach the webhook
# service using the `url` field instead of a service.
url:
{}
# host:
# Enables default network policies for webhooks.
networkPolicy:
# Create network policies for the webhooks.
enabled: false
# Ingress rule for the webhook network policy. By default, it allows all
# inbound traffic.
# +docs:property
ingress:
- from:
- ipBlock:
cidr: 0.0.0.0/0
# Egress rule for the webhook network policy. By default, it allows all
# outbound traffic to ports 80 and 443, as well as DNS ports.
# +docs:property
egress:
- ports:
- port: 80
protocol: TCP
- port: 443
protocol: TCP
- port: 53
protocol: TCP
- port: 53
protocol: UDP
# On OpenShift and OKD, the Kubernetes API server listens on.
# port 6443.
- port: 6443
protocol: TCP
to:
- ipBlock:
cidr: 0.0.0.0/0
# Additional volumes to add to the cert-manager controller pod.
volumes: []
# Additional volume mounts to add to the cert-manager controller container.
volumeMounts: []
# enableServiceLinks indicates whether information about services should be
# injected into the pod's environment variables, matching the syntax of Docker
# links.
enableServiceLinks: false
# +docs:section=CA Injector
cainjector:
# Create the CA Injector deployment
enabled: true
# The number of replicas of the cert-manager cainjector to run.
#
# The default is 1, but in production set this to 2 or 3 to provide high
# availability.
#
# If `replicas > 1`, consider setting `cainjector.podDisruptionBudget.enabled=true`.
#
# Note that cert-manager uses leader election to ensure that there can
# only be a single instance active at a time.
replicaCount: 3
# This is used to configure options for the cainjector pod.
# It allows setting options that are usually provided via flags.
# An APIVersion and Kind must be specified in your values.yaml file.
# Flags override options that are set here.
#
# For example:
# apiVersion: cainjector.config.cert-manager.io/v1alpha1
# kind: CAInjectorConfiguration
# logging:
# verbosity: 2
# format: text
# leaderElectionConfig:
# namespace: kube-system
config: {}
# Deployment update strategy for the cert-manager cainjector deployment.
# For more information, see the [Kubernetes documentation](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#strategy).
#
# For example:
# strategy:
# type: RollingUpdate
# rollingUpdate:
# maxSurge: 0
# maxUnavailable: 1
strategy: {}
# Pod Security Context to be set on the cainjector component Pod
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
# Container Security Context to be set on the cainjector component container
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
containerSecurityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
podDisruptionBudget:
# Enable or disable the PodDisruptionBudget resource.
#
# This prevents downtime during voluntary disruptions such as during a Node upgrade.
# For example, the PodDisruptionBudget will block `kubectl drain`
# if it is used on the Node where the only remaining cert-manager
# Pod is currently running.
enabled: false
# `minAvailable` configures the minimum available pods for disruptions. It can either be set to
# an integer (e.g. 1) or a percentage value (e.g. 25%).
# Cannot be used if `maxUnavailable` is set.
# +docs:property
# minAvailable: 1
# `maxUnavailable` configures the maximum unavailable pods for disruptions. It can either be set to
# an integer (e.g. 1) or a percentage value (e.g. 25%).
# Cannot be used if `minAvailable` is set.
# +docs:property
# maxUnavailable: 1
# Optional additional annotations to add to the cainjector Deployment.
# +docs:property
# deploymentAnnotations: {}
# Optional additional annotations to add to the cainjector Pods.
# +docs:property
# podAnnotations: {}
# Additional command line flags to pass to cert-manager cainjector binary.
# To see all available flags run `docker run quay.io/jetstack/cert-manager-cainjector:<version> --help`.
extraArgs: []
# Enable profiling for cainjector.
# - --enable-profiling=true
# Comma separated list of feature gates that should be enabled on the
# cainjector pod.
featureGates: ""
# Resources to provide to the cert-manager cainjector pod.
#
# For example:
# requests:
# cpu: 10m
# memory: 32Mi
#
# For more information, see [Resource Management for Pods and Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
resources: {}
# The nodeSelector on Pods tells Kubernetes to schedule Pods on the nodes with
# matching labels.
# For more information, see [Assigning Pods to Nodes](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/).
#
# This default ensures that Pods are only scheduled to Linux nodes.
# It prevents Pods being scheduled to Windows nodes in a mixed OS cluster.
# +docs:property
nodeSelector:
kubernetes.io/os: linux
# A Kubernetes Affinity, if required. For more information, see [Affinity v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#affinity-v1-core).
#
# For example:
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: foo.bar.com/role
# operator: In
# values:
# - master
affinity: {}
# A list of Kubernetes Tolerations, if required. For more information, see [Toleration v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#toleration-v1-core).
#
# For example:
# tolerations:
# - key: foo.bar.com/role
# operator: Equal
# value: master
# effect: NoSchedule
tolerations: []
# A list of Kubernetes TopologySpreadConstraints, if required. For more information, see [Topology spread constraint v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#topologyspreadconstraint-v1-core).
#
# For example:
# topologySpreadConstraints:
# - maxSkew: 2
# topologyKey: topology.kubernetes.io/zone
# whenUnsatisfiable: ScheduleAnyway
# labelSelector:
# matchLabels:
# app.kubernetes.io/instance: cert-manager
# app.kubernetes.io/component: controller
topologySpreadConstraints: []
# Optional additional labels to add to the CA Injector Pods.
podLabels: {}
image:
# The container registry to pull the cainjector image from.
# +docs:property
# registry: quay.io
# The container image for the cert-manager cainjector
# +docs:property
repository: quay.io/jetstack/cert-manager-cainjector
# Override the image tag to deploy by setting this variable.
# If no value is set, the chart's appVersion will be used.
# +docs:property
# tag: vX.Y.Z
# Setting a digest will override any tag.
# +docs:property
# digest: sha256:0e072dddd1f7f8fc8909a2ca6f65e76c5f0d2fcfb8be47935ae3457e8bbceb20
# Kubernetes imagePullPolicy on Deployment.
pullPolicy: IfNotPresent
serviceAccount:
# Specifies whether a service account should be created.
create: true
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template
# +docs:property
# name: ""
# Optional additional annotations to add to the controller's Service Account.
# +docs:property
# annotations: {}
# Optional additional labels to add to the cainjector's Service Account.
# +docs:property
# labels: {}
# Automount API credentials for a Service Account.
automountServiceAccountToken: true
# Automounting API credentials for a particular pod.
# +docs:property
# automountServiceAccountToken: true
# Additional volumes to add to the cert-manager controller pod.
volumes: []
# Additional volume mounts to add to the cert-manager controller container.
volumeMounts: []
# enableServiceLinks indicates whether information about services should be
# injected into the pod's environment variables, matching the syntax of Docker
# links.
enableServiceLinks: false
# +docs:section=ACME Solver
acmesolver:
image:
# The container registry to pull the acmesolver image from.
# +docs:property
# registry: quay.io
# The container image for the cert-manager acmesolver.
# +docs:property
repository: quay.io/jetstack/cert-manager-acmesolver
# Override the image tag to deploy by setting this variable.
# If no value is set, the chart's appVersion is used.
# +docs:property
# tag: vX.Y.Z
# Setting a digest will override any tag.
# +docs:property
# digest: sha256:0e072dddd1f7f8fc8909a2ca6f65e76c5f0d2fcfb8be47935ae3457e8bbceb20
# Kubernetes imagePullPolicy on Deployment.
pullPolicy: IfNotPresent
# +docs:section=Startup API Check
# This startupapicheck is a Helm post-install hook that waits for the webhook
# endpoints to become available.
# The check is implemented using a Kubernetes Job - if you are injecting mesh
# sidecar proxies into cert-manager pods, ensure that they
# are not injected into this Job's pod. Otherwise, the installation may time out
# owing to the Job never being completed because the sidecar proxy does not exit.
# For more information, see [this note](https://github.com/cert-manager/cert-manager/pull/4414).
startupapicheck:
# Enables the startup api check.
enabled: true
# Pod Security Context to be set on the startupapicheck component Pod.
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
securityContext:
runAsNonRoot: true
seccompProfile:
type: RuntimeDefault
# Container Security Context to be set on the controller component container.
# For more information, see [Configure a Security Context for a Pod or Container](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/).
# +docs:property
containerSecurityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
# Timeout for 'kubectl check api' command.
timeout: 1m
# Job backoffLimit
backoffLimit: 4
# Optional additional annotations to add to the startupapicheck Job.
# +docs:property
jobAnnotations:
helm.sh/hook: post-install
helm.sh/hook-weight: "1"
helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded
# Optional additional annotations to add to the startupapicheck Pods.
# +docs:property
# podAnnotations: {}
# Additional command line flags to pass to startupapicheck binary.
# To see all available flags run `docker run quay.io/jetstack/cert-manager-startupapicheck:<version> --help`.
#
# Verbose logging is enabled by default so that if startupapicheck fails, you
# can know what exactly caused the failure. Verbose logs include details of
# the webhook URL, IP address and TCP connect errors for example.
# +docs:property
extraArgs:
- -v
# Resources to provide to the cert-manager controller pod.
#
# For example:
# requests:
# cpu: 10m
# memory: 32Mi
#
# For more information, see [Resource Management for Pods and Containers](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/).
resources: {}
# The nodeSelector on Pods tells Kubernetes to schedule Pods on the nodes with
# matching labels.
# For more information, see [Assigning Pods to Nodes](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/).
#
# This default ensures that Pods are only scheduled to Linux nodes.
# It prevents Pods being scheduled to Windows nodes in a mixed OS cluster.
# +docs:property
nodeSelector:
kubernetes.io/os: linux
# A Kubernetes Affinity, if required. For more information, see [Affinity v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#affinity-v1-core).
# For example:
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: foo.bar.com/role
# operator: In
# values:
# - master
affinity: {}
# A list of Kubernetes Tolerations, if required. For more information, see [Toleration v1 core](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.27/#toleration-v1-core).
#
# For example:
# tolerations:
# - key: foo.bar.com/role
# operator: Equal
# value: master
# effect: NoSchedule
tolerations: []
# Optional additional labels to add to the startupapicheck Pods.
podLabels: {}
image:
# The container registry to pull the startupapicheck image from.
# +docs:property
# registry: quay.io
# The container image for the cert-manager startupapicheck.
# +docs:property
repository: quay.io/jetstack/cert-manager-startupapicheck
# Override the image tag to deploy by setting this variable.
# If no value is set, the chart's appVersion is used.
# +docs:property
# tag: vX.Y.Z
# Setting a digest will override any tag.
# +docs:property
# digest: sha256:0e072dddd1f7f8fc8909a2ca6f65e76c5f0d2fcfb8be47935ae3457e8bbceb20
# Kubernetes imagePullPolicy on Deployment.
pullPolicy: IfNotPresent
rbac:
# annotations for the startup API Check job RBAC and PSP resources.
# +docs:property
annotations:
helm.sh/hook: post-install
helm.sh/hook-weight: "-5"
helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded
# Automounting API credentials for a particular pod.
# +docs:property
# automountServiceAccountToken: true
serviceAccount:
# Specifies whether a service account should be created.
create: true
# The name of the service account to use.
# If not set and create is true, a name is generated using the fullname template.
# +docs:property
# name: ""
# Optional additional annotations to add to the Job's Service Account.
# +docs:property
annotations:
helm.sh/hook: post-install
helm.sh/hook-weight: "-5"
helm.sh/hook-delete-policy: before-hook-creation,hook-succeeded
# Automount API credentials for a Service Account.
# +docs:property
automountServiceAccountToken: true
# Optional additional labels to add to the startupapicheck's Service Account.
# +docs:property
# labels: {}
# Additional volumes to add to the cert-manager controller pod.
volumes: []
# Additional volume mounts to add to the cert-manager controller container.
volumeMounts: []
# enableServiceLinks indicates whether information about services should be
# injected into pod's environment variables, matching the syntax of Docker
# links.
enableServiceLinks: false
# Create dynamic manifests via values.
#
# For example:
# extraObjects:
# - |
# apiVersion: v1
# kind: ConfigMap
# metadata:
# name: '{{ template "cert-manager.name" . }}-extra-configmap'
extraObjects: []
- Lets git it
git add .
git commit -m "k8s infra cert manager deploy"
git push
Fluxcd is doing the following under the hood | Cert Manager
- Helm repo add
helm repo add jetstack https://charts.jetstack.io --force-update
- Helm repo install
helm install cert-manager --namespace kube-system --version v1.15.1 jetstack/cert-manager
Kubernetes check | Cert Manager
- Kubectl switch to the
kube-systemnamespace
kubectl config set-context --current --namespace=kube-system
- Kubectl show me the pods
kubectl get pods -n kube-system | grep cert

Great we now have infrastructure for managing certificates!
Metallb Load-Balancer For Bare Metal Kubernetes Deployment
With Metallb we will setup a unique IP address on our home network to expose the Microservices running in our Kubernetes cluster. A public cloud provider would give you this during the deployment of your Kubernetes cluster but since we are the cloud we need to provide it and thats where Metallb comes in.
- Kubectl quick reference here
- Helm cheat sheet here
- Helm Chart on ArtifactHub here
- Metallb concepts here
Helm-Repository | Metallb
- Lets add the Metallb Helm repository
- A Helm repository is a collection of Helm charts that are made available for download and installation
- Helm repositories serve as centralised locations where Helm charts can be stored, shared, and managed
- Create a file called
metallb.yamlin thehelm-repositoriesdirectory and paste the following YAML - Choose an IP address on your private home network that does not fall inside your DHCP pool for Metallb to use
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: metallb
namespace: infrastructure
spec:
interval: 60m
url: https://metallb.github.io/metallb
Helm-Release | Metallb
- Lets create a Helm release for Metallb
- A Helm release is an instance of a Helm chart running in a Kubernetes cluster
- Each release is a deployment of a particular version of a chart with a specific configuration
- Create a file called
metallb.yamlin thehelm-releasesdirectory and paste the following YAML
---
apiVersion: helm.toolkit.fluxcd.io/v2beta2
kind: HelmRelease
metadata:
name: metallb
namespace: infrastructure
spec:
interval: 60m
releaseName: metallb
chart:
spec:
chart: metallb
version: v0.14.8 # Simply change the version to upgrade
sourceRef:
kind: HelmRepository
name: metallb
interval: 10m
# values: your values go here to override the default values
values:
# Default values for metallb.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
imagePullSecrets: []
nameOverride: ""
fullnameOverride: ""
loadBalancerClass: ""
# To configure MetalLB, you must specify ONE of the following two
# options.
rbac:
# create specifies whether to install and use RBAC rules.
create: true
prometheus:
# scrape annotations specifies whether to add Prometheus metric
# auto-collection annotations to pods. See
# https://github.com/prometheus/prometheus/blob/release-2.1/documentation/examples/prometheus-kubernetes.yml
# for a corresponding Prometheus configuration. Alternatively, you
# may want to use the Prometheus Operator
# (https://github.com/coreos/prometheus-operator) for more powerful
# monitoring configuration. If you use the Prometheus operator, this
# can be left at false.
scrapeAnnotations: false
# port both controller and speaker will listen on for metrics
metricsPort: 7472
# if set, enables rbac proxy on the controller and speaker to expose
# the metrics via tls.
# secureMetricsPort: 9120
# the name of the secret to be mounted in the speaker pod
# to expose the metrics securely. If not present, a self signed
# certificate to be used.
speakerMetricsTLSSecret: ""
# the name of the secret to be mounted in the controller pod
# to expose the metrics securely. If not present, a self signed
# certificate to be used.
controllerMetricsTLSSecret: ""
# prometheus doens't have the permission to scrape all namespaces so we give it permission to scrape metallb's one
rbacPrometheus: true
# the service account used by prometheus
# required when " .Values.prometheus.rbacPrometheus == true " and " .Values.prometheus.podMonitor.enabled=true or prometheus.serviceMonitor.enabled=true "
serviceAccount: ""
# the namespace where prometheus is deployed
# required when " .Values.prometheus.rbacPrometheus == true " and " .Values.prometheus.podMonitor.enabled=true or prometheus.serviceMonitor.enabled=true "
namespace: ""
# the image to be used for the kuberbacproxy container
rbacProxy:
repository: gcr.io/kubebuilder/kube-rbac-proxy
tag: v0.12.0
pullPolicy:
# Prometheus Operator PodMonitors
podMonitor:
# enable support for Prometheus Operator
enabled: false
# optional additionnal labels for podMonitors
additionalLabels: {}
# optional annotations for podMonitors
annotations: {}
# Job label for scrape target
jobLabel: "app.kubernetes.io/name"
# Scrape interval. If not set, the Prometheus default scrape interval is used.
interval:
# metric relabel configs to apply to samples before ingestion.
metricRelabelings: []
# - action: keep
# regex: 'kube_(daemonset|deployment|pod|namespace|node|statefulset).+'
# sourceLabels: [__name__]
# relabel configs to apply to samples before ingestion.
relabelings: []
# - sourceLabels: [__meta_kubernetes_pod_node_name]
# separator: ;
# regex: ^(.*)$
# target_label: nodename
# replacement: $1
# action: replace
# Prometheus Operator ServiceMonitors. To be used as an alternative
# to podMonitor, supports secure metrics.
serviceMonitor:
# enable support for Prometheus Operator
enabled: false
speaker:
# optional additional labels for the speaker serviceMonitor
additionalLabels: {}
# optional additional annotations for the speaker serviceMonitor
annotations: {}
# optional tls configuration for the speaker serviceMonitor, in case
# secure metrics are enabled.
tlsConfig:
insecureSkipVerify: true
controller:
# optional additional labels for the controller serviceMonitor
additionalLabels: {}
# optional additional annotations for the controller serviceMonitor
annotations: {}
# optional tls configuration for the controller serviceMonitor, in case
# secure metrics are enabled.
tlsConfig:
insecureSkipVerify: true
# Job label for scrape target
jobLabel: "app.kubernetes.io/name"
# Scrape interval. If not set, the Prometheus default scrape interval is used.
interval:
# metric relabel configs to apply to samples before ingestion.
metricRelabelings: []
# - action: keep
# regex: 'kube_(daemonset|deployment|pod|namespace|node|statefulset).+'
# sourceLabels: [__name__]
# relabel configs to apply to samples before ingestion.
relabelings: []
# - sourceLabels: [__meta_kubernetes_pod_node_name]
# separator: ;
# regex: ^(.*)$
# target_label: nodename
# replacement: $1
# action: replace
# Prometheus Operator alertmanager alerts
prometheusRule:
# enable alertmanager alerts
enabled: false
# optional additionnal labels for prometheusRules
additionalLabels: {}
# optional annotations for prometheusRules
annotations: {}
# MetalLBStaleConfig
staleConfig:
enabled: true
labels:
severity: warning
# MetalLBConfigNotLoaded
configNotLoaded:
enabled: true
labels:
severity: warning
# MetalLBAddressPoolExhausted
addressPoolExhausted:
enabled: true
labels:
severity: alert
addressPoolUsage:
enabled: true
thresholds:
- percent: 75
labels:
severity: warning
- percent: 85
labels:
severity: warning
- percent: 95
labels:
severity: alert
# MetalLBBGPSessionDown
bgpSessionDown:
enabled: true
labels:
severity: alert
extraAlerts: []
# controller contains configuration specific to the MetalLB cluster
# controller.
controller:
enabled: true
# -- Controller log level. Must be one of: `all`, `debug`, `info`, `warn`, `error` or `none`
logLevel: info
# command: /controller
# webhookMode: enabled
image:
repository: quay.io/metallb/controller
tag:
pullPolicy:
## @param controller.updateStrategy.type Metallb controller deployment strategy type.
## ref: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#strategy
## e.g:
## strategy:
## type: RollingUpdate
## rollingUpdate:
## maxSurge: 25%
## maxUnavailable: 25%
##
strategy:
type: RollingUpdate
serviceAccount:
# Specifies whether a ServiceAccount should be created
create: true
# The name of the ServiceAccount to use. If not set and create is
# true, a name is generated using the fullname template
name: ""
annotations: {}
securityContext:
runAsNonRoot: true
# nobody
runAsUser: 65534
fsGroup: 65534
resources:
{}
# limits:
# cpu: 100m
# memory: 100Mi
nodeSelector: {}
tolerations: []
priorityClassName: ""
runtimeClassName: ""
affinity: {}
podAnnotations: {}
labels: {}
livenessProbe:
enabled: true
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
enabled: true
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
tlsMinVersion: "VersionTLS12"
tlsCipherSuites: ""
extraContainers: []
# speaker contains configuration specific to the MetalLB speaker
# daemonset.
speaker:
enabled: true
# command: /speaker
# -- Speaker log level. Must be one of: `all`, `debug`, `info`, `warn`, `error` or `none`
logLevel: info
tolerateMaster: true
memberlist:
enabled: true
mlBindPort: 7946
mlBindAddrOverride: ""
mlSecretKeyPath: "/etc/ml_secret_key"
excludeInterfaces:
enabled: true
# ignore the exclude-from-external-loadbalancer label
ignoreExcludeLB: false
image:
repository: quay.io/metallb/speaker
tag:
pullPolicy:
## @param speaker.updateStrategy.type Speaker daemonset strategy type
## ref: https://kubernetes.io/docs/tasks/manage-daemon/update-daemon-set/
##
updateStrategy:
## StrategyType
## Can be set to RollingUpdate or OnDelete
##
type: RollingUpdate
serviceAccount:
# Specifies whether a ServiceAccount should be created
create: true
# The name of the ServiceAccount to use. If not set and create is
# true, a name is generated using the fullname template
name: ""
annotations: {}
securityContext: {}
## Defines a secret name for the controller to generate a memberlist encryption secret
## By default secretName: {{ "metallb.fullname" }}-memberlist
##
# secretName:
resources:
{}
# limits:
# cpu: 100m
# memory: 100Mi
nodeSelector: {}
tolerations: []
priorityClassName: ""
affinity: {}
## Selects which runtime class will be used by the pod.
runtimeClassName: ""
podAnnotations: {}
labels: {}
livenessProbe:
enabled: true
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
enabled: true
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
startupProbe:
enabled: true
failureThreshold: 30
periodSeconds: 5
# frr contains configuration specific to the MetalLB FRR container,
# for speaker running alongside FRR.
frr:
enabled: true
image:
repository: quay.io/frrouting/frr
tag: 9.1.0
pullPolicy:
metricsPort: 7473
resources: {}
# if set, enables a rbac proxy sidecar container on the speaker to
# expose the frr metrics via tls.
# secureMetricsPort: 9121
reloader:
resources: {}
frrMetrics:
resources: {}
extraContainers: []
crds:
enabled: true
validationFailurePolicy: Fail
# frrk8s contains the configuration related to using an frrk8s instance
# (github.com/metallb/frr-k8s) as the backend for the BGP implementation.
# This allows configuring additional frr parameters in combination to those
# applied by MetalLB.
frrk8s:
# if set, enables frrk8s as a backend. This is mutually exclusive to frr
# mode.
enabled: false
external: false
namespace: ""
- Lets git it
git add .
git commit -m "k8s infra metallb deploy"
git push
Fluxcd is doing the following under the hood | Metallb
- Helm repo add
helm repo add metallb https://metallb.github.io/metallb --force-update
- Helm install MetalLB in the
infrastructurenamespace
helm install metallb metallb/metallb -n infrastructure
Kubernetes check | Metallb
- Kubectl switch to the
infrastructurenamespace
kubectl config set-context --current --namespace=infrastructure
- Kubectl show me the Metallb pods in the
infrastructurenamespace
kubectl get pods -n infrastructure

- Now lets enable L2 Advertisement and setup our IP pool
- Create
metallb.yamlin themanifest folderand paste the YAML below intometallb.yamland runkubectl apply -f metallb.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: default-pool
namespace: infrastructure
spec:
addresses:
- 192.168.0.151-192.168.0.151 # Amend this to match your private ip address pool
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: default-pool
namespace: infrastructure
spec:
ipAddressPools:
- default-pool
- Kubectl show me all CRDs for Metallb
kubectl get crds | grep metallb

- Kubectl show me the IP address pools for Metallb
kubectl get ipaddresspools.metallb.io -n infrastructure

Epic we have a working load balancer using a single IP address which will act as a gateway into our Kubernetes cluster which we can control with Traefik Proxy and which Traefik Proxy can bind to.
Traefik the Cloud Native Proxy Deployment
With Traefik Proxy we can now direct traffic destined for our Microservices into the Kubernetes cluster and protect our endpoints using a combination of entrypoints, routers, services, providers and middlewares.
- Kubectl quick reference here
- Helm cheat sheet here
- Traefik docs here
- Traefik EntryPoints
- Traefik Routers
- Traefik Services can be divided into two groups
Traefik ServicesandKubernetes Services - Traefik Providers
- Traefik Helm Chart on ArtifactHub here
Helm-Repository | Traefik
- Lets add the Traefik Helm repository
- A Helm repository is a collection of Helm charts that are made available for download and installation
- Helm repositories serve as centralised locations where Helm charts can be stored, shared, and managed
- Create a file called
traefik.yamlin thehelm-repositoriesdirectory and paste the following YAML
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: traefik
namespace: infrastructure
spec:
interval: 60m
url: https://traefik.github.io/charts
Helm-Release | Traefik
- Lets create a Helm release for Traefik
- A Helm release is an instance of a Helm chart running in a Kubernetes cluster
- Each release is a deployment of a particular version of a chart with a specific configuration
- Create a file called
traefik.yamlin thehelm-releasesdirectory and paste the following YAML
Helm Chart Configuration Highlights
- You may want to edit these to suit your environment
deployment:
replicas: 3
# -- Create a default IngressClass for Traefik
ingressClass:
enabled: true
isDefaultClass: true
# The gatekeeper to your Microservices
ingressRoute:
dashboard:
# -- Create an IngressRoute for the dashboard
enabled: true
# -- Additional ingressRoute annotations (e.g. for kubernetes.io/ingress.class)
annotations: {}
# -- Additional ingressRoute labels (e.g. for filtering IngressRoute by custom labels)
labels: {}
# -- The router match rule used for the dashboard ingressRoute
matchRule: Host(`<add your fqdn here>`) #PathPrefix(`/dashboard`) || PathPrefix(`/api`)
# -- Specify the allowed entrypoints to use for the dashboard ingress route, (e.g. traefik, web, websecure).
# By default, it's using traefik entrypoint, which is not exposed.
# /!\ Do not expose your dashboard without any protection over the internet /!\
entryPoints: ["web", "websecure"]
# -- Additional ingressRoute middlewares (e.g. for authentication)
providers:
kubernetesCRD:
# -- Load Kubernetes IngressRoute provider
enabled: true # Personally I would leave this enabled
kubernetesIngress:
# -- Load Kubernetes Ingress provider
enabled: true
# Lets make that CSI NFS Driver work
persistence:
# -- Enable persistence using Persistent Volume Claims
# ref: http://kubernetes.io/docs/user-guide/persistent-volumes/
# It can be used to store TLS certificates, see `storage` in certResolvers
enabled: true
---
apiVersion: helm.toolkit.fluxcd.io/v2beta2
kind: HelmRelease
metadata:
name: traefik
namespace: infrastructure
spec:
interval: 60m
releaseName: traefik
chart:
spec:
chart: traefik
version: 31.0.0 # Simply change the version to upgrade
sourceRef:
kind: HelmRepository
name: traefik
interval: 10m
# values: your values go here to override the default values
values:
# Default values for Traefikk
# This is a YAML-formatted file.
# Declare variables to be passed into templates
image:
# -- Traefik image host registry
registry: docker.io
# -- Traefik image repository
repository: traefik
# -- defaults to appVersion
tag:
# -- Traefik image pull policy
pullPolicy: IfNotPresent
# -- Add additional label to all resources
commonLabels: {}
deployment:
# -- Enable deployment
enabled: true
# -- Deployment or DaemonSet
kind: Deployment
# -- Number of pods of the deployment (only applies when kind == Deployment)
replicas: 3
# -- Number of old history to retain to allow rollback (If not set, default Kubernetes value is set to 10)
# revisionHistoryLimit: 1
# -- Amount of time (in seconds) before Kubernetes will send the SIGKILL signal if Traefik does not shut down
terminationGracePeriodSeconds: 60
# -- The minimum number of seconds Traefik needs to be up and running before the DaemonSet/Deployment controller considers it available
minReadySeconds: 0
## Override the liveness/readiness port. This is useful to integrate traefik
## with an external Load Balancer that performs healthchecks.
## Default: ports.traefik.port
# healthchecksPort: 9000
## Override the liveness/readiness host. Useful for getting ping to respond on non-default entryPoint.
## Default: ports.traefik.hostIP if set, otherwise Pod IP
# healthchecksHost: localhost
## Override the liveness/readiness scheme. Useful for getting ping to
## respond on websecure entryPoint.
# healthchecksScheme: HTTPS
## Override the readiness path.
## Default: /ping
# readinessPath: /ping
# Override the liveness path.
# Default: /ping
# livenessPath: /ping
# -- Additional deployment annotations (e.g. for jaeger-operator sidecar injection)
annotations: {}
# -- Additional deployment labels (e.g. for filtering deployment by custom labels)
labels: {}
# -- Additional pod annotations (e.g. for mesh injection or prometheus scraping)
# It supports templating. One can set it with values like traefik/name: '{{ template "traefik.name" . }}'
podAnnotations: {}
# -- Additional Pod labels (e.g. for filtering Pod by custom labels)
podLabels: {}
# -- Additional containers (e.g. for metric offloading sidecars)
additionalContainers: []
# https://docs.datadoghq.com/developers/dogstatsd/unix_socket/?tab=host
# - name: socat-proxy
# image: alpine/socat:1.0.5
# args: ["-s", "-u", "udp-recv:8125", "unix-sendto:/socket/socket"]
# volumeMounts:
# - name: dsdsocket
# mountPath: /socket
# -- Additional volumes available for use with initContainers and additionalContainers
additionalVolumes: []
# - name: dsdsocket
# hostPath:
# path: /var/run/statsd-exporter
# -- Additional initContainers (e.g. for setting file permission as shown below)
initContainers: []
# The "volume-permissions" init container is required if you run into permission issues.
# Related issue: https://github.com/traefik/traefik-helm-chart/issues/396
# - name: volume-permissions
# image: busybox:latest
# command: ["sh", "-c", "touch /data/acme.json; chmod -v 600 /data/acme.json"]
# volumeMounts:
# - name: data
# mountPath: /data
# -- Use process namespace sharing
shareProcessNamespace: false
# -- Custom pod DNS policy. Apply if `hostNetwork: true`
# dnsPolicy: ClusterFirstWithHostNet
# -- Custom pod [DNS config](https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.30/#poddnsconfig-v1-core)
dnsConfig: {}
# -- Custom [host aliases](https://kubernetes.io/docs/tasks/network/customize-hosts-file-for-pods/)
hostAliases: []
# -- Pull secret for fetching traefik container image
imagePullSecrets: []
# -- Pod lifecycle actions
lifecycle: {}
# preStop:
# exec:
# command: ["/bin/sh", "-c", "sleep 40"]
# postStart:
# httpGet:
# path: /ping
# port: 9000
# host: localhost
# scheme: HTTP
# -- Set a runtimeClassName on pod
runtimeClassName:
# -- [Pod Disruption Budget](https://kubernetes.io/docs/reference/kubernetes-api/policy-resources/pod-disruption-budget-v1/)
podDisruptionBudget:
enabled:
maxUnavailable:
minAvailable:
# -- Create a default IngressClass for Traefik
ingressClass:
enabled: true
isDefaultClass: true
# name: my-custom-class
core:
# -- Can be used to use globally v2 router syntax
# See https://doc.traefik.io/traefik/v3.0/migration/v2-to-v3/#new-v3-syntax-notable-changes
defaultRuleSyntax:
# Traefik experimental features
experimental:
# -- Enable traefik experimental plugins
plugins: {}
# demo:
# moduleName: github.com/traefik/plugindemo
# version: v0.2.1
kubernetesGateway:
# -- Enable traefik experimental GatewayClass CRD
enabled: false
## Routes are restricted to namespace of the gateway by default.
## https://gateway-api.sigs.k8s.io/references/spec/#gateway.networking.k8s.io/v1beta1.FromNamespaces
# namespacePolicy: All
# certificate:
# group: "core"
# kind: "Secret"
# name: "mysecret"
# -- By default, Gateway would be created to the Namespace you are deploying Traefik to.
# You may create that Gateway in another namespace, setting its name below:
# namespace: default
# Additional gateway annotations (e.g. for cert-manager.io/issuer)
# annotations:
# cert-manager.io/issuer: letsencrypt
ingressRoute:
dashboard:
# -- Create an IngressRoute for the dashboard
enabled: true
# -- Additional ingressRoute annotations (e.g. for kubernetes.io/ingress.class)
annotations: {}
# -- Additional ingressRoute labels (e.g. for filtering IngressRoute by custom labels)
labels: {}
# -- The router match rule used for the dashboard ingressRoute
matchRule: Host(`<add your fqdn here>`) #PathPrefix(`/dashboard`) || PathPrefix(`/api`)
# -- Specify the allowed entrypoints to use for the dashboard ingress route, (e.g. traefik, web, websecure).
# By default, it's using traefik entrypoint, which is not exposed.
# /!\ Do not expose your dashboard without any protection over the internet /!\
entryPoints: ["web", "websecure"]
# -- Additional ingressRoute middlewares (e.g. for authentication)
middlewares: []
# -- TLS options (e.g. secret containing certificate)
tls: {}
healthcheck:
# -- Create an IngressRoute for the healthcheck probe
enabled: false
# -- Additional ingressRoute annotations (e.g. for kubernetes.io/ingress.class)
annotations: {}
# -- Additional ingressRoute labels (e.g. for filtering IngressRoute by custom labels)
labels: {}
# -- The router match rule used for the healthcheck ingressRoute
matchRule: PathPrefix(`/ping`)
# -- Specify the allowed entrypoints to use for the healthcheck ingress route, (e.g. traefik, web, websecure).
# By default, it's using traefik entrypoint, which is not exposed.
entryPoints: ["traefik"]
# -- Additional ingressRoute middlewares (e.g. for authentication)
middlewares: []
# -- TLS options (e.g. secret containing certificate)
tls: {}
updateStrategy:
# -- Customize updateStrategy: RollingUpdate or OnDelete
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 1
readinessProbe:
# -- The number of consecutive failures allowed before considering the probe as failed.
failureThreshold: 1
# -- The number of seconds to wait before starting the first probe.
initialDelaySeconds: 2
# -- The number of seconds to wait between consecutive probes.
periodSeconds: 10
# -- The minimum consecutive successes required to consider the probe successful.
successThreshold: 1
# -- The number of seconds to wait for a probe response before considering it as failed.
timeoutSeconds: 2
livenessProbe:
# -- The number of consecutive failures allowed before considering the probe as failed.
failureThreshold: 3
# -- The number of seconds to wait before starting the first probe.
initialDelaySeconds: 2
# -- The number of seconds to wait between consecutive probes.
periodSeconds: 10
# -- The minimum consecutive successes required to consider the probe successful.
successThreshold: 1
# -- The number of seconds to wait for a probe response before considering it as failed.
timeoutSeconds: 2
# -- Define [Startup Probe](https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#define-startup-probes)
startupProbe:
providers:
kubernetesCRD:
# -- Load Kubernetes IngressRoute provider
enabled: true
# -- Allows IngressRoute to reference resources in namespace other than theirs
allowCrossNamespace: false
# -- Allows to reference ExternalName services in IngressRoute
allowExternalNameServices: false
# -- Allows to return 503 when there is no endpoints available
allowEmptyServices: false
# -- When the parameter is set, only resources containing an annotation with the same value are processed. Otherwise, resources missing the annotation, having an empty value, or the value traefik are processed. It will also set required annotation on Dashboard and Healthcheck IngressRoute when enabled.
ingressClass:
# labelSelector: environment=production,method=traefik
# -- Array of namespaces to watch. If left empty, Traefik watches all namespaces.
namespaces: []
# -- Defines whether to use Native Kubernetes load-balancing mode by default.
nativeLBByDefault:
kubernetesIngress:
# -- Load Kubernetes Ingress provider
enabled: true
# -- Allows to reference ExternalName services in Ingress
allowExternalNameServices: false
# -- Allows to return 503 when there is no endpoints available
allowEmptyServices: false
# -- When ingressClass is set, only Ingresses containing an annotation with the same value are processed. Otherwise, Ingresses missing the annotation, having an empty value, or the value traefik are processed.
ingressClass:
# labelSelector: environment=production,method=traefik
# -- Array of namespaces to watch. If left empty, Traefik watches all namespaces.
namespaces: []
# - "default"
# Disable cluster IngressClass Lookup - Requires Traefik V3.
# When combined with rbac.namespaced: true, ClusterRole will not be created and ingresses must use kubernetes.io/ingress.class annotation instead of spec.ingressClassName.
disableIngressClassLookup: false
# IP used for Kubernetes Ingress endpoints
publishedService:
enabled: false
# Published Kubernetes Service to copy status from. Format: namespace/servicename
# By default this Traefik service
# pathOverride: ""
# -- Defines whether to use Native Kubernetes load-balancing mode by default.
nativeLBByDefault:
file:
# -- Create a file provider
enabled: false
# -- Allows Traefik to automatically watch for file changes
watch: true
# -- File content (YAML format, go template supported) (see https://doc.traefik.io/traefik/providers/file/)
# content:
providers:
file:
directory: /manifests/traefik-dynamic-config.yaml
# -- Add volumes to the traefik pod. The volume name will be passed to tpl.
# This can be used to mount a cert pair or a configmap that holds a config.toml file.
# After the volume has been mounted, add the configs into traefik by using the `additionalArguments` list below, eg:
# `additionalArguments:
# - "--providers.file.filename=/config/dynamic.toml"
# - "--ping"
# - "--ping.entrypoint=web"`
volumes: []
# - name: public-cert
# mountPath: "/certs"
# type: secret
# - name: '{{ printf "%s-configs" .Release.Name }}'
# mountPath: "/config"
# type: configMap
# -- Additional volumeMounts to add to the Traefik container
additionalVolumeMounts: []
# -- For instance when using a logshipper for access logs
# - name: traefik-logs
# mountPath: /var/log/traefik
logs:
general:
# -- Set [logs format](https://doc.traefik.io/traefik/observability/logs/#format)
# @default common
format:
# By default, the level is set to ERROR.
# -- Alternative logging levels are DEBUG, PANIC, FATAL, ERROR, WARN, and INFO.
level: INFO
access:
# -- To enable access logs
enabled: false
# -- Set [access log format](https://doc.traefik.io/traefik/observability/access-logs/#format)
format:
# filePath: "/var/log/traefik/access.log
# -- Set [bufferingSize](https://doc.traefik.io/traefik/observability/access-logs/#bufferingsize)
bufferingSize:
# -- Set [filtering](https://docs.traefik.io/observability/access-logs/#filtering)
filters: {}
# statuscodes: "200,300-302"
# retryattempts: true
# minduration: 10ms
# -- Enables accessLogs for internal resources. Default: false.
addInternals:
fields:
general:
# -- Available modes: keep, drop, redact.
defaultmode: keep
# -- Names of the fields to limit.
names: {}
## Examples:
# ClientUsername: drop
# -- [Limit logged fields or headers](https://doc.traefik.io/traefik/observability/access-logs/#limiting-the-fieldsincluding-headers)
headers:
# -- Available modes: keep, drop, redact.
defaultmode: drop
names: {}
metrics:
## -- Enable metrics for internal resources. Default: false
addInternals:
## -- Prometheus is enabled by default.
## -- It can be disabled by setting "prometheus: null"
prometheus:
# -- Entry point used to expose metrics.
entryPoint: metrics
## Enable metrics on entry points. Default=true
# addEntryPointsLabels: false
## Enable metrics on routers. Default=false
# addRoutersLabels: true
## Enable metrics on services. Default=true
# addServicesLabels: false
## Buckets for latency metrics. Default="0.1,0.3,1.2,5.0"
# buckets: "0.5,1.0,2.5"
## When manualRouting is true, it disables the default internal router in
## order to allow creating a custom router for prometheus@internal service.
# manualRouting: true
service:
# -- Create a dedicated metrics service to use with ServiceMonitor
enabled:
labels:
annotations:
# -- When set to true, it won't check if Prometheus Operator CRDs are deployed
disableAPICheck:
serviceMonitor:
# -- Enable optional CR for Prometheus Operator. See EXAMPLES.md for more details.
enabled: false
metricRelabelings:
relabelings:
jobLabel:
interval:
honorLabels:
scrapeTimeout:
honorTimestamps:
enableHttp2:
followRedirects:
additionalLabels:
namespace:
namespaceSelector:
prometheusRule:
# -- Enable optional CR for Prometheus Operator. See EXAMPLES.md for more details.
enabled: false
additionalLabels:
namespace:
# datadog:
# ## Address instructs exporter to send metrics to datadog-agent at this address.
# address: "127.0.0.1:8125"
# ## The interval used by the exporter to push metrics to datadog-agent. Default=10s
# # pushInterval: 30s
# ## The prefix to use for metrics collection. Default="traefik"
# # prefix: traefik
# ## Enable metrics on entry points. Default=true
# # addEntryPointsLabels: false
# ## Enable metrics on routers. Default=false
# # addRoutersLabels: true
# ## Enable metrics on services. Default=true
# # addServicesLabels: false
# influxdb2:
# ## Address instructs exporter to send metrics to influxdb v2 at this address.
# address: localhost:8086
# ## Token with which to connect to InfluxDB v2.
# token: xxx
# ## Organisation where metrics will be stored.
# org: ""
# ## Bucket where metrics will be stored.
# bucket: ""
# ## The interval used by the exporter to push metrics to influxdb. Default=10s
# # pushInterval: 30s
# ## Additional labels (influxdb tags) on all metrics.
# # additionalLabels:
# # env: production
# # foo: bar
# ## Enable metrics on entry points. Default=true
# # addEntryPointsLabels: false
# ## Enable metrics on routers. Default=false
# # addRoutersLabels: true
# ## Enable metrics on services. Default=true
# # addServicesLabels: false
# statsd:
# ## Address instructs exporter to send metrics to statsd at this address.
# address: localhost:8125
# ## The interval used by the exporter to push metrics to influxdb. Default=10s
# # pushInterval: 30s
# ## The prefix to use for metrics collection. Default="traefik"
# # prefix: traefik
# ## Enable metrics on entry points. Default=true
# # addEntryPointsLabels: false
# ## Enable metrics on routers. Default=false
# # addRoutersLabels: true
# ## Enable metrics on services. Default=true
# # addServicesLabels: false
otlp:
# -- Set to true in order to enable the OpenTelemetry metrics
enabled: false
# -- Enable metrics on entry points. Default: true
addEntryPointsLabels:
# -- Enable metrics on routers. Default: false
addRoutersLabels:
# -- Enable metrics on services. Default: true
addServicesLabels:
# -- Explicit boundaries for Histogram data points. Default: [.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10]
explicitBoundaries:
# -- Interval at which metrics are sent to the OpenTelemetry Collector. Default: 10s
pushInterval:
http:
# -- Set to true in order to send metrics to the OpenTelemetry Collector using HTTP.
enabled: false
# -- Format: <scheme>://<host>:<port><path>. Default: http://localhost:4318/v1/metrics
endpoint:
# -- Additional headers sent with metrics by the reporter to the OpenTelemetry Collector.
headers:
## Defines the TLS configuration used by the reporter to send metrics to the OpenTelemetry Collector.
tls:
# -- The path to the certificate authority, it defaults to the system bundle.
ca:
# -- The path to the public certificate. When using this option, setting the key option is required.
cert:
# -- The path to the private key. When using this option, setting the cert option is required.
key:
# -- When set to true, the TLS connection accepts any certificate presented by the server regardless of the hostnames it covers.
insecureSkipVerify:
grpc:
# -- Set to true in order to send metrics to the OpenTelemetry Collector using gRPC
enabled: false
# -- Format: <scheme>://<host>:<port><path>. Default: http://localhost:4318/v1/metrics
endpoint:
# -- Allows reporter to send metrics to the OpenTelemetry Collector without using a secured protocol.
insecure:
## Defines the TLS configuration used by the reporter to send metrics to the OpenTelemetry Collector.
tls:
# -- The path to the certificate authority, it defaults to the system bundle.
ca:
# -- The path to the public certificate. When using this option, setting the key option is required.
cert:
# -- The path to the private key. When using this option, setting the cert option is required.
key:
# -- When set to true, the TLS connection accepts any certificate presented by the server regardless of the hostnames it covers.
insecureSkipVerify:
## Tracing
# -- https://doc.traefik.io/traefik/observability/tracing/overview/
tracing:
# -- Enables tracing for internal resources. Default: false.
addInternals:
otlp:
# -- See https://doc.traefik.io/traefik/v3.0/observability/tracing/opentelemetry/
enabled: false
http:
# -- Set to true in order to send metrics to the OpenTelemetry Collector using HTTP.
enabled: false
# -- Format: <scheme>://<host>:<port><path>. Default: http://localhost:4318/v1/metrics
endpoint:
# -- Additional headers sent with metrics by the reporter to the OpenTelemetry Collector.
headers:
## Defines the TLS configuration used by the reporter to send metrics to the OpenTelemetry Collector.
tls:
# -- The path to the certificate authority, it defaults to the system bundle.
ca:
# -- The path to the public certificate. When using this option, setting the key option is required.
cert:
# -- The path to the private key. When using this option, setting the cert option is required.
key:
# -- When set to true, the TLS connection accepts any certificate presented by the server regardless of the hostnames it covers.
insecureSkipVerify:
grpc:
# -- Set to true in order to send metrics to the OpenTelemetry Collector using gRPC
enabled: false
# -- Format: <scheme>://<host>:<port><path>. Default: http://localhost:4318/v1/metrics
endpoint:
# -- Allows reporter to send metrics to the OpenTelemetry Collector without using a secured protocol.
insecure:
## Defines the TLS configuration used by the reporter to send metrics to the OpenTelemetry Collector.
tls:
# -- The path to the certificate authority, it defaults to the system bundle.
ca:
# -- The path to the public certificate. When using this option, setting the key option is required.
cert:
# -- The path to the private key. When using this option, setting the cert option is required.
key:
# -- When set to true, the TLS connection accepts any certificate presented by the server regardless of the hostnames it covers.
insecureSkipVerify:
# -- Global command arguments to be passed to all traefik's pods
globalArguments:
- "--global.checknewversion"
# - "--global.sendanonymoususage"
# -- Additional arguments to be passed at Traefik's binary
# See [CLI Reference](https://docs.traefik.io/reference/static-configuration/cli/)
# Use curly braces to pass values: `helm install --set="additionalArguments={--providers.kubernetesingress.ingressclass=traefik-internal,--log.level=DEBUG}"`
additionalArguments: []
# - "--providers.kubernetesingress.ingressclass=traefik-internal"
# - "--log.level=DEBUG"
# -- Environment variables to be passed to Traefik's binary
# @default -- See _values.yaml_
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
# -- Environment variables to be passed to Traefik's binary from configMaps or secrets
envFrom: []
ports:
traefik:
port: 9000
# -- Use hostPort if set.
# hostPort: 9000
#
# -- Use hostIP if set. If not set, Kubernetes will default to 0.0.0.0, which
# means it's listening on all your interfaces and all your IPs. You may want
# to set this value if you need traefik to listen on specific interface
# only.
# hostIP: 192.168.100.10
# Defines whether the port is exposed if service.type is LoadBalancer or
# NodePort.
#
# -- You SHOULD NOT expose the traefik port on production deployments.
# If you want to access it from outside your cluster,
# use `kubectl port-forward` or create a secure ingress
expose:
default: false
# -- The exposed port for this service
exposedPort: 9000
# -- The port protocol (TCP/UDP)
protocol: TCP
web:
## -- Enable this entrypoint as a default entrypoint. When a service doesn't explicitly set an entrypoint it will only use this entrypoint.
# asDefault: true
port: 8000
# hostPort: 8000
# containerPort: 8000
expose:
default: true
exposedPort: 80
## -- Different target traefik port on the cluster, useful for IP type LB
# targetPort: 80
# The port protocol (TCP/UDP)
protocol: TCP
# -- Use nodeport if set. This is useful if you have configured Traefik in a
# LoadBalancer.
# nodePort: 32080
# Port Redirections
# Added in 2.2, you can make permanent redirects via entrypoints.
# https://docs.traefik.io/routing/entrypoints/#redirection
# redirectTo:
# port: websecure
# (Optional)
# priority: 10
# permanent: true
#
# -- Trust forwarded headers information (X-Forwarded-*).
# forwardedHeaders:
# trustedIPs: []
# insecure: false
#
# -- Enable the Proxy Protocol header parsing for the entry point
# proxyProtocol:
# trustedIPs: []
# insecure: false
#
# -- Set transport settings for the entrypoint; see also
# https://doc.traefik.io/traefik/routing/entrypoints/#transport
transport:
respondingTimeouts:
readTimeout:
writeTimeout:
idleTimeout:
lifeCycle:
requestAcceptGraceTimeout:
graceTimeOut:
keepAliveMaxRequests:
keepAliveMaxTime:
websecure:
## -- Enable this entrypoint as a default entrypoint. When a service doesn't explicitly set an entrypoint it will only use this entrypoint.
# asDefault: true
port: 8443
# hostPort: 8443
# containerPort: 8443
expose:
default: true
exposedPort: 443
## -- Different target traefik port on the cluster, useful for IP type LB
# targetPort: 80
## -- The port protocol (TCP/UDP)
protocol: TCP
# nodePort: 32443
## -- Specify an application protocol. This may be used as a hint for a Layer 7 load balancer.
# appProtocol: https
#
## -- Enable HTTP/3 on the entrypoint
## Enabling it will also enable http3 experimental feature
## https://doc.traefik.io/traefik/routing/entrypoints/#http3
## There are known limitations when trying to listen on same ports for
## TCP & UDP (Http3). There is a workaround in this chart using dual Service.
## https://github.com/kubernetes/kubernetes/issues/47249#issuecomment-587960741
http3:
enabled: true
# advertisedPort: 4443
#
# -- Trust forwarded headers information (X-Forwarded-*).
# forwardedHeaders:
# trustedIPs: []
# insecure: false
#
# -- Enable the Proxy Protocol header parsing for the entry point
# proxyProtocol:
# trustedIPs: []
# insecure: false
#
# -- Set transport settings for the entrypoint; see also
# https://doc.traefik.io/traefik/routing/entrypoints/#transport
transport:
respondingTimeouts:
readTimeout:
writeTimeout:
idleTimeout:
lifeCycle:
requestAcceptGraceTimeout:
graceTimeOut:
keepAliveMaxRequests:
keepAliveMaxTime:
#
## Set TLS at the entrypoint
## https://doc.traefik.io/traefik/routing/entrypoints/#tls
tls:
enabled: true
# this is the name of a TLSOption definition
options: ""
certResolver: ""
domains: []
# - main: example.com
# sans:
# - foo.example.com
# - bar.example.com
#
# -- One can apply Middlewares on an entrypoint
# https://doc.traefik.io/traefik/middlewares/overview/
# https://doc.traefik.io/traefik/routing/entrypoints/#middlewares
# -- /!\ It introduces here a link between your static configuration and your dynamic configuration /!\
# It follows the provider naming convention: https://doc.traefik.io/traefik/providers/overview/#provider-namespace
# middlewares:
# - namespace-name1@kubernetescrd
# - namespace-name2@kubernetescrd
middlewares: []
metrics:
# -- When using hostNetwork, use another port to avoid conflict with node exporter:
# https://github.com/prometheus/prometheus/wiki/Default-port-allocations
port: 9100
# hostPort: 9100
# Defines whether the port is exposed if service.type is LoadBalancer or
# NodePort.
#
# -- You may not want to expose the metrics port on production deployments.
# If you want to access it from outside your cluster,
# use `kubectl port-forward` or create a secure ingress
expose:
default: false
# -- The exposed port for this service
exposedPort: 9100
# -- The port protocol (TCP/UDP)
protocol: TCP
# -- TLS Options are created as [TLSOption CRDs](https://doc.traefik.io/traefik/https/tls/#tls-options)
# When using `labelSelector`, you'll need to set labels on tlsOption accordingly.
# See EXAMPLE.md for details.
tlsOptions: {}
# -- TLS Store are created as [TLSStore CRDs](https://doc.traefik.io/traefik/https/tls/#default-certificate). This is useful if you want to set a default certificate. See EXAMPLE.md for details.
tlsStore: {}
service:
enabled: true
## -- Single service is using `MixedProtocolLBService` feature gate.
## -- When set to false, it will create two Service, one for TCP and one for UDP.
single: true
type: LoadBalancer
# -- Additional annotations applied to both TCP and UDP services (e.g. for cloud provider specific config)
annotations: {}
# -- Additional annotations for TCP service only
annotationsTCP: {}
# -- Additional annotations for UDP service only
annotationsUDP: {}
# -- Additional service labels (e.g. for filtering Service by custom labels)
labels: {}
# -- Additional entries here will be added to the service spec.
# -- Cannot contain type, selector or ports entries.
spec: {}
# externalTrafficPolicy: Cluster
# loadBalancerIP: "1.2.3.4"
# clusterIP: "2.3.4.5"
loadBalancerSourceRanges: []
# - 192.168.0.1/32
# - 172.16.0.0/16
## -- Class of the load balancer implementation
# loadBalancerClass: service.k8s.aws/nlb
externalIPs: []
# - 1.2.3.4
## One of SingleStack, PreferDualStack, or RequireDualStack.
# ipFamilyPolicy: SingleStack
## List of IP families (e.g. IPv4 and/or IPv6).
## ref: https://kubernetes.io/docs/concepts/services-networking/dual-stack/#services
# ipFamilies:
# - IPv4
# - IPv6
##
additionalServices: {}
## -- An additional and optional internal Service.
## Same parameters as external Service
# internal:
# type: ClusterIP
# # labels: {}
# # annotations: {}
# # spec: {}
# # loadBalancerSourceRanges: []
# # externalIPs: []
# # ipFamilies: [ "IPv4","IPv6" ]
autoscaling:
# -- Create HorizontalPodAutoscaler object.
# See EXAMPLES.md for more details.
enabled: false
persistence:
# -- Enable persistence using Persistent Volume Claims
# ref: http://kubernetes.io/docs/user-guide/persistent-volumes/
# It can be used to store TLS certificates, see `storage` in certResolvers
enabled: true
name: data
# existingClaim: ""
accessMode: ReadWriteOnce
size: 128Mi
storageClass: "nfs-csi-traefik" # Update with your storage class
# volumeName: ""
path: /data
annotations: {}
# -- Only mount a subpath of the Volume into the pod
# subPath: ""
# -- Certificates resolvers configuration.
# Ref: https://doc.traefik.io/traefik/https/acme/#certificate-resolvers
# See EXAMPLES.md for more details.
certResolvers: {}
# -- If hostNetwork is true, runs traefik in the host network namespace
# To prevent unschedulabel pods due to port collisions, if hostNetwork=true
# and replicas>1, a pod anti-affinity is recommended and will be set if the
# affinity is left as default.
hostNetwork: false
# -- Whether Role Based Access Control objects like roles and rolebindings should be created
rbac:
enabled: true
# If set to false, installs ClusterRole and ClusterRoleBinding so Traefik can be used across namespaces.
# If set to true, installs Role and RoleBinding instead of ClusterRole/ClusterRoleBinding. Providers will only watch target namespace.
# When combined with providers.kubernetesIngress.disableIngressClassLookup: true and Traefik V3, ClusterRole to watch IngressClass is also disabled.
namespaced: false
# Enable user-facing roles
# https://kubernetes.io/docs/reference/access-authn-authz/rbac/#user-facing-roles
# aggregateTo: [ "admin" ]
# List of Kubernetes secrets that are accessible for Traefik. If empty, then access is granted to every secret.
secretResourceNames: []
# -- Enable to create a PodSecurityPolicy and assign it to the Service Account via RoleBinding or ClusterRoleBinding
podSecurityPolicy:
enabled: false
# -- The service account the pods will use to interact with the Kubernetes API
serviceAccount:
# If set, an existing service account is used
# If not set, a service account is created automatically using the fullname template
name: ""
# -- Additional serviceAccount annotations (e.g. for oidc authentication)
serviceAccountAnnotations: {}
# -- [Resources](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/) for `traefik` container.
resources: {}
# -- This example pod anti-affinity forces the scheduler to put traefik pods
# -- on nodes where no other traefik pods are scheduled.
# It should be used when hostNetwork: true to prevent port conflicts
affinity: {}
# podAntiAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# - labelSelector:
# matchLabels:
# app.kubernetes.io/name: '{{ template "traefik.name" . }}'
# app.kubernetes.io/instance: '{{ .Release.Name }}-{{ .Release.Namespace }}'
# topologyKey: kubernetes.io/hostname
# -- nodeSelector is the simplest recommended form of node selection constraint.
nodeSelector: {}
# -- Tolerations allow the scheduler to schedule pods with matching taints.
tolerations: []
# -- You can use topology spread constraints to control
# how Pods are spread across your cluster among failure-domains.
topologySpreadConstraints: []
# This example topologySpreadConstraints forces the scheduler to put traefik pods
# on nodes where no other traefik pods are scheduled.
# - labelSelector:
# matchLabels:
# app: '{{ template "traefik.name" . }}'
# maxSkew: 1
# topologyKey: kubernetes.io/hostname
# whenUnsatisfiable: DoNotSchedule
# -- [Pod Priority and Preemption](https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption/)
priorityClassName: ""
# -- [SecurityContext](https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#security-context-1)
# @default -- See _values.yaml_
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: [ALL]
readOnlyRootFilesystem: true
# -- [Pod Security Context](https://kubernetes.io/docs/reference/kubernetes-api/workload-resources/pod-v1/#security-context)
# @default -- See _values.yaml_
podSecurityContext:
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65532
#
# -- Extra objects to deploy (value evaluated as a template)
#
# In some cases, it can avoid the need for additional, extended or adhoc deployments.
# See #595 for more details and traefik/tests/values/extra.yaml for example.
extraObjects: []
# -- This field override the default Release Namespace for Helm.
# It will not affect optional CRDs such as `ServiceMonitor` and `PrometheusRules`
namespaceOverride:
## -- This field override the default app.kubernetes.io/instance label for all Objects.
instanceLabelOverride:
# Traefik Hub configuration. See https://doc.traefik.io/traefik-hub/
hub:
# -- Name of `Secret` with key 'token' set to a valid license token.
# It enables API Gateway.
token:
apimanagement:
# -- Set to true in order to enable API Management. Requires a valid license token.
enabled:
admission:
# -- WebHook admission server listen address. Default: "0.0.0.0:9943".
listenAddr:
# -- Certificate of the WebHook admission server. Default: "hub-agent-cert".
secretName:
ratelimit:
redis:
# -- Enable Redis Cluster. Default: true.
cluster:
# -- Database used to store information. Default: "0".
database:
# -- Endpoints of the Redis instances to connect to. Default: "".
endpoints:
# -- The username to use when connecting to Redis endpoints. Default: "".
username:
# -- The password to use when connecting to Redis endpoints. Default: "".
password:
sentinel:
# -- Name of the set of main nodes to use for main selection. Required when using Sentinel. Default: "".
masterset:
# -- Username to use for sentinel authentication (can be different from endpoint username). Default: "".
username:
# -- Password to use for sentinel authentication (can be different from endpoint password). Default: "".
password:
# -- Timeout applied on connection with redis. Default: "0s".
timeout:
tls:
# -- Path to the certificate authority used for the secured connection.
ca:
# -- Path to the public certificate used for the secure connection.
cert:
# -- Path to the private key used for the secure connection.
key:
# -- When insecureSkipVerify is set to true, the TLS connection accepts any certificate presented by the server. Default: false.
insecureSkipVerify:
# Enable export of errors logs to the platform. Default: true.
sendlogs:
Gimlet Manifest Folder | Traefik
- The folks at Traefik put this nice piece of logic in the Helm Chart that allows you to create a config file which is dynamically monitored by Traefik
- I am using this to manage the Lets Encrypt certicate renewal in conjunction with Cloudflare
- I have
DISABLEDthis logic in the above Helm Chart values config for now until I have done the Cloudflare part of the blog
file:
# -- Create a file provider
enabled: false
# -- Allows Traefik to automatically watch for file changes
watch: true
# -- File content (YAML format, go template supported) (see https://doc.traefik.io/traefik/providers/file/)
# content:
providers:
file:
directory: /manifests/traefik-dynamic-config.yaml
- Create the following file
traefik-dynamic-config.yamland add the following YAML config if you are using Cloudflare - Otherwise refer to these configuration examples for the Traefik Helm Chart here
---
# Kubernetes secret containing the Cloudflare api token
apiVersion: v1
kind: Secret
metadata:
name: cloudflare
namespace: infrastructure
type: Opaque
stringData:
api-token: "<add your cloudflare api token>"
---
# Certificate configuration and renewal structure stored in cert-manager
# !!!!WARNING!!!! If you want to use cert-manager you need to have this installed
# before you initiate the certifcate configuration
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: cloudflare
namespace: infrastructure
spec:
acme:
email: <add your email address>
server: https://acme-v02.api.letsencrypt.org/directory
privateKeySecretRef:
name: cloudflare-key
solvers:
- dns01:
cloudflare:
email: sachajw@gmail.com
apiTokenSecretRef:
name: cloudflare
key: api-token
- Lets git it
git add .
git commit -m "k8s infra traefik proxy deploy"
git push
Fluxcd is doing the following under the hood | Traefik
- Helm repo add
helm repo add traefik https://traefik.github.io/charts --force-update
- Helm install Traefik
helm install traefik traefik/traefik --namespace=traefik
- Kubectl switch to the infrastructure namespace
kubectl config set-context --current --namespace=infrastructure
- Kubectl show me the pods for Traefik
kubectl get pods -n infrastructure

- Kubectl show me all CRDs for Traefik
kubectl get crds | grep traefik
Traefik Dashboard
- You will need a DNS record created either on your DNS server or in localhosts file to access the dashboard
- Edit localhosts on Linux and Mac with sudo rights
sudo vi /etc/hostsby addingyour private IPandtraefik.yourdomain.tlde.g.traefik.pangarabbit.com - Edit Windows localhosts file here as administrator
windows\System32\drivers\etc\hostsby addingyour private ip and traefik.yourdomain.your tlde.g.traefik.pangarabbit.com - Remember to note that all things infrastructure are created in the
infrastructurenamespace
The IngressRoute for the Traefik Dashboard is created from this configuration in the Traefik Helm Chart values
ingressRoute:
dashboard:
# -- Create an IngressRoute for the dashboard
enabled: true
# -- Additional ingressRoute annotations (e.g. for kubernetes.io/ingress.class)
annotations: {}
# -- Additional ingressRoute labels (e.g. for filtering IngressRoute by custom labels)
labels: {}
# -- The router match rule used for the dashboard ingressRoute
matchRule: Host(`traefik.pangarabbit.com`) #PathPrefix(`/dashboard`) || PathPrefix(`/api`)
# -- Specify the allowed entrypoints to use for the dashboard ingress route, (e.g. traefik, web, websecure).
# By default, it's using traefik entrypoint, which is not exposed.
# /!\ Do not expose your dashboard without any protection over the internet /!\
entryPoints: ["websecure"]
# -- Additional ingressRoute middlewares (e.g. for authentication)
middlewares: []
# -- TLS options (e.g. secret containing certificate)
tls:
default:
defaultCertificate:
secretName: wildcard-pangarabbit-com-tls
- Kubectl show me the Traefik ingress routes
kubectl get ingressroutes.traefik.io -n infrastructure

- Kubectl show me that the Traefik service has claimed our Metallb single IP address
kubectl get svc -n infrastructure

- Here is a view of the services for the
infrastructurenamespace
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
cert-manager ClusterIP 10.152.183.37 <none> 9402/TCP 5d1h
cert-manager-webhook ClusterIP 10.152.183.90 <none> 443/TCP 5d1h
external-secrets-controller-webhook ClusterIP 10.152.183.141 <none> 443/TCP 6d7h
gimlet-agent ClusterIP 10.152.183.103 <none> 80/TCP 7d1h
image-builder ClusterIP 10.152.183.247 <none> 9000/TCP 7d1h
localstack NodePort 10.152.183.166 <none> 4566:31566/TCP,4510:30519/TCP,4511:30385/TCP,4512:31571/TCP,4513:31900/TCP,4514:30675/TCP,4515:31564/TCP,4516:32556/TCP,4517:32025/TCP,4518:31320/TCP,4519:31642/TCP,4520:31655/TCP,4521:30246/TCP,4522:31741/TCP,4523:30728/TCP,4524:32385/TCP,4525:30533/TCP,4526:30722/TCP,4527:32290/TCP,4528:32541/TCP,4529:30146/TCP,4530:32489/TCP,4531:31950/TCP,4532:30786/TCP,4533:32477/TCP,4534:31403/TCP,4535:30868/TCP,4536:31489/TCP,4537:32623/TCP,4538:31764/TCP,4539:31650/TCP,4540:31094/TCP,4541:31456/TCP,4542:32746/TCP,4543:32402/TCP,4544:31807/TCP,4545:31245/TCP,4546:31154/TCP,4547:31639/TCP,4548:31716/TCP,4549:30928/TCP,4550:30408/TCP,4551:31849/TCP,4552:30100/TCP,4553:31715/TCP,4554:30729/TCP,4555:32343/TCP,4556:30110/TCP,4557:31042/TCP,4558:31806/TCP,4559:30239/TCP 3d18h
metallb-webhook-service ClusterIP 10.152.183.136 <none> 443/TCP 3d8h
ms-compitem-crud NodePort 10.152.183.88 <none> 80:30149/TCP 2d2h
ms-dep-pkg-cud NodePort 10.152.183.151 <none> 80:32165/TCP 2d2h
ms-dep-pkg-r NodePort 10.152.183.36 <none> 80:30377/TCP 2d2h
ms-general NodePort 10.152.183.225 <none> 8080:31066/TCP 2d2h
ms-nginx NodePort 10.152.183.100 <none> 80:30493/TCP,443:32727/TCP 2d2h
ms-scorecard NodePort 10.152.183.80 <none> 80:31522/TCP 2d2h
ms-textfile-crud NodePort 10.152.183.237 <none> 80:32707/TCP 2d2h
ms-ui NodePort 10.152.183.99 <none> 8080:31941/TCP 2d2h
ms-validate-user NodePort 10.152.183.61 <none> 80:32446/TCP 2d2h
nats ClusterIP 10.152.183.98 <none> 4222/TCP 3d18h
nats-headless ClusterIP None <none> 4222/TCP,8222/TCP 3d18h
netdata ClusterIP 10.152.183.110 <none> 19999/TCP 3d18h
traefik LoadBalancer 10.152.183.135 192.168.0.151 80:31662/TCP,443:30850/TCP 4d19h
Brilliant our Traefik Proxy has claimed the IP.
What you see is the traefik service with the TYPE LoadBalancer and it has claimed the Metallb IP that we assigned. A CLUSTER-IP is only accessible inside Kubernetes. So now with Metallb and Traefik we have built a bridge between the outside world and our internal Kubernetes world. Traefik comes with some self discovery magic in the form of providers which allows Traefik to query provider APIs to find relevant information about routing and then dynamically update the routes.
Hopefully you should be able to access your dashboard at the FQDN e.g. traefik.pangarabbit.com
Further reading | Traefik
If you would like to dig deeper into Traefiks API capabilities please go to the following:
- Traefik Hub API Gateway
- Traefik Enterprise
- Traefik Hub
- Watch Upgrade Traefik Proxy to API Gateway and API Management in Seconds on YouTube
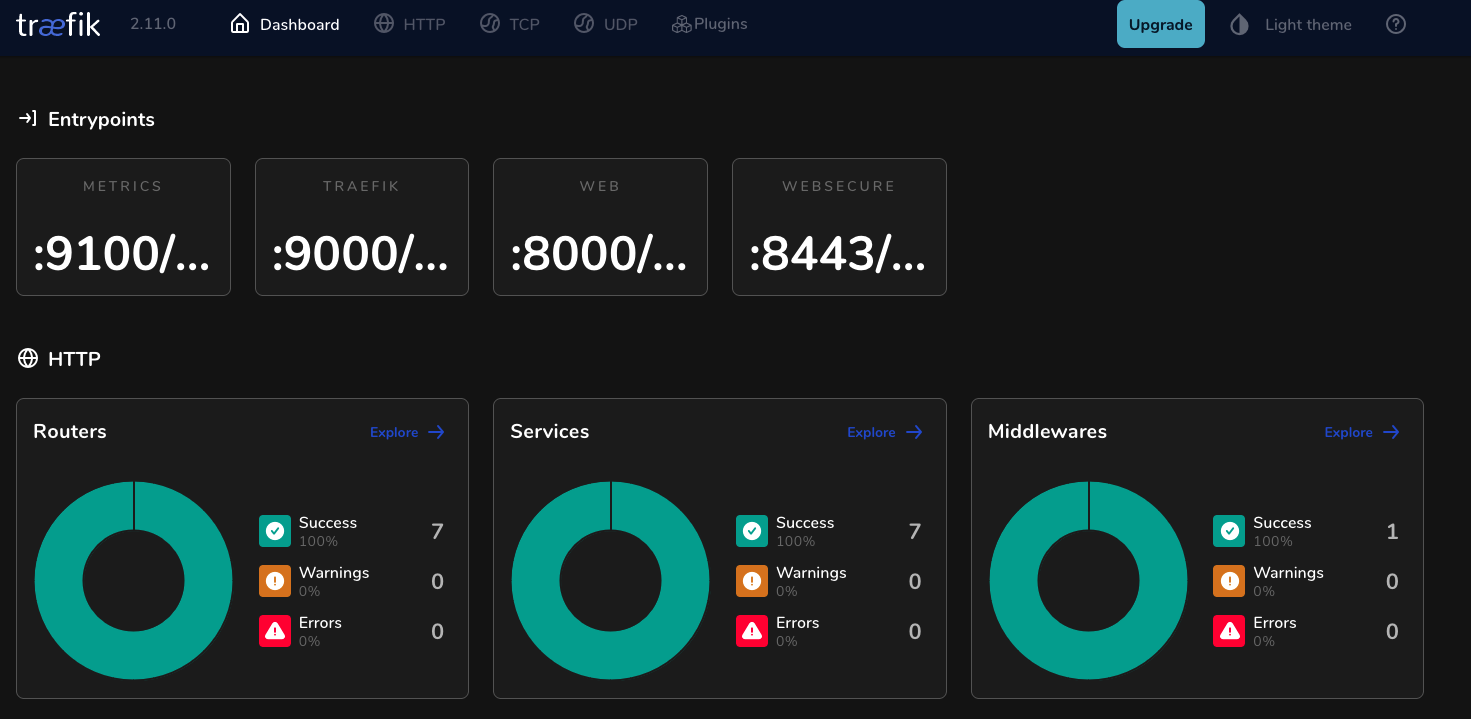
Ortelius The Ultimate Evidence Store
Well done for making it this far! We have made it to the point where we can deploy Ortelius into our Kubernetes cluster and configure Ortelius to be accessed through Traefik Proxy.
- Kubectl quick reference guide here
- Helm cheat sheet here
- Ortelius on GitHub here
- Ortelius docs here
- Ortelius Helm Chart on ArtifactHub here
The Microservice we are most interested in is ms-nginx which is the gateway to all the backing microservices for Ortelius. We are going to deploy Ortelius using Gimlet and Fluxcd then configure Traefik to send requests to ms-nginx which should allow us to load the Ortelius frontend.
Ortelius Microservice GitHub repos
You can find all the Ortelius Microservices here on GitHub
Helm-Repository | Ortelius
- Lets add the Ortelius Helm repository
- A Helm repository is a collection of Helm charts that are made available for download and installation
- Helm repositories serve as centralised locations where Helm charts can be stored, shared, and managed
- Create a file called
ortelius.yamlin the helm-repositories directory and paste the following YAML
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: ortelius
namespace: infrastructure
spec:
interval: 60m
url: https://ortelius.github.io/ortelius-charts/
Helm-Release | Ortelius
- Lets create a Helm release for Ortelius
- A Helm release is an instance of a Helm chart running in a Kubernetes cluster
- Each release is a deployment of a particular version of a chart with a specific configuration
- Create a file called
ortelius.yamlin the helm-releases directory and paste the following YAML
---
apiVersion: helm.toolkit.fluxcd.io/v2beta2
kind: HelmRelease
metadata:
name: ortelius
namespace: infrastructure
spec:
interval: 60m
timeout: 10m
releaseName: ortelius
chart:
spec:
chart: ortelius
version: v10.0.4533 # Simply change the version to upgrade
sourceRef:
kind: HelmRepository
name: ortelius
interval: 10m
# values: your values go here to override the default values
values:
ms-general:
dbpass: postgres # --set ms-general.dbpass=postgres
# Set the PostgreSQL database password
global:
postgresql:
enabled: true
nginxController:
enabled: true # --set global.nginxController.enabled=true
# Sets the ingress controller which could be one of default Nginx, AWS LB or Google LB
# Refer to the Helm Chart in ArtifactHub here https://artifacthub.io/packages/helm/ortelius/ortelius
ms-nginx:
ingress:
type: k3d # --set ms-nginx.ingress.type=k3d`
# This setting is for enabling the Traefik Class so that Traefik is made aware of Ortelius
# K3d https://k3d.io/v5.6.0/ is a lightweight Kubernetes deployment which uses Traefik as the default
dnsname: ortelius.pangarabbit.com # --set ms-nginx.ingress.dnsname=<your domain name goes here>
# The URL that will go in your browser to access the Ortelius frontend
Fluxcd is doing the following under the hood | Ortelius
- Helm repo add
helm repo add ortelius https://ortelius.github.io/ortelius-charts/ --force-update
- Helm install Ortelius
helm upgrade --install ortelius ortelius/ortelius \
--set ms-general.dbpass=postgres \
--set global.postgresql.enabled=true \
--set global.nginxController.enabled=true \
--set ms-nginx.ingress.type=k3d \
--set ms-nginx.ingress.dnsname=<your domain name goes here> \
--version "${ORTELIUS_VERSION}" --namespace ortelius
Kubernetes check | Ortelius
- Kubectl switch to the infrastructure namespace
kubectl config set-context --current --namespace=infrastructure
- Kubectl show me the pods for Ortelius
kubectl get pods -n infrastructure | grep ms
msstands for microservice
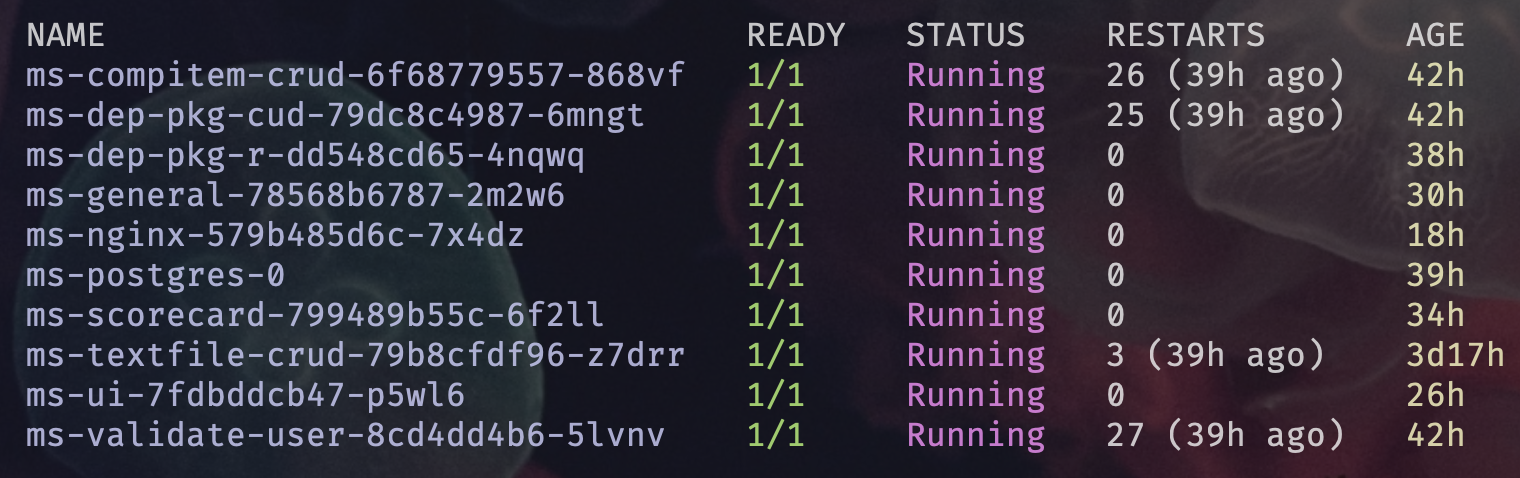
You should now be able to reach the Ortelius frontend in your browser using the domain name you chose for example mine was http://ortelius.pangarabbit.com and see the login screen as in the graphic. You will get a certificate error but just allow access for now until we sort out the certificate with Cloudflare.

FYI make sure you backup your persistent volumes on the NFS server
Conclusion
By this stage you should have three Pi’s each with MicroK8s, NFS CSI Driver, Cert Manager, Traefik, Ortelius and a NFS server up and running with Gimlet as the UI to Fluxcd which is all part of the management of our GitOps environment. Stay tuned for Part 4 where we unleash Cloudflare, LetsEncrypt with Traefik for automatic certificate renewal to provide secure services behind a single entrypoint.
Happy alien hunting…….
Next Steps
How to Bake an Ortelius Pi | Part 4 | Cloudflare Certificates and Traefik
